Hermes Agent深度解析:构建能够持续学习和成长的AI系统
Abstract
Hermes Agent 是 Nous Research 推出的一个可进化 Agent 系统,它通过 Memory、Session Search、Skills、Curator 等模块,实现了从“会回答”到“会做事”的转变。本文将深入解析 Hermes 的架构设计,探讨如何构建一个能够持续学习和成长的 AI 系统。
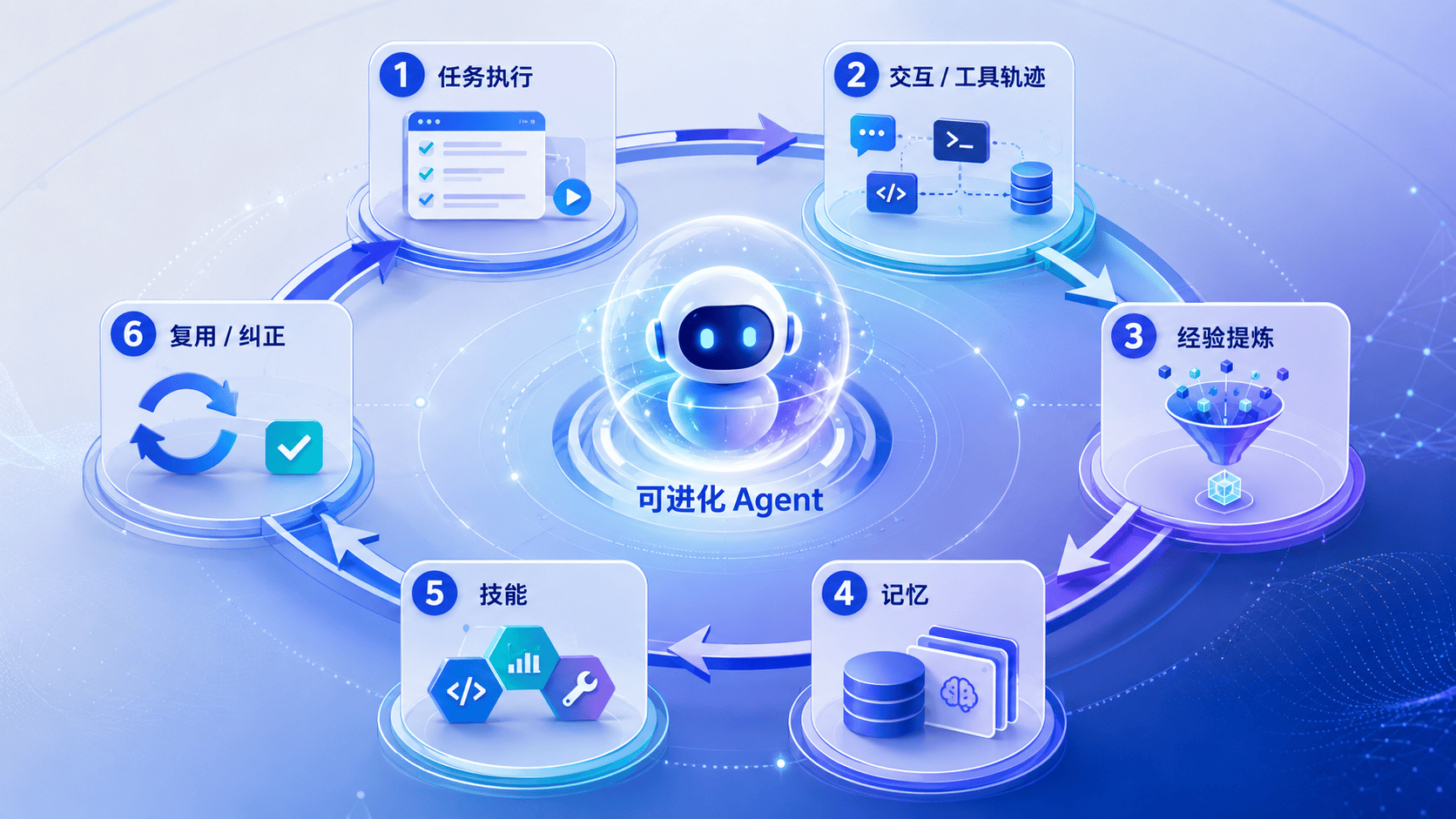
过去一年,Agent 系统的讨论已经从“能不能调用工具”转向了另一个更难的问题:Agent 能不能越用越强?
很多系统表面上也有“记忆”。历史对话进向量库,用户偏好进 prompt,跑起来似乎也能记住一点东西。但我越来越觉得,问题不在“记住多少”,而在“经验有没有去处”。
一次任务做成了,系统到底学到了什么?是多了一段很快会过期的聊天记录,还是多了一条下次真能复用的做事方法?这个区别,决定了你做的是一个会话系统,还是一个会慢慢长出能力的 Agent 系统。
我会借 Nous Research 的 Hermes Agent 来讨论这件事,不是因为它把模型、工具、运行环境都堆得很满,而是因为它认真处理了这个问题。它不只是帮你自动化完成任务,还会记住项目、生成技能、把能力延续到下一次会话里。
本文想讨论的,不是"Hermes 有哪些功能",而是另一件更底层的事:如果你真的想做一个可自我进化的 Agent,经验到底该放在哪里,系统又该怎样把这些经验接住。
一、为什么“经验闭环”比“长上下文”更重要
我们在设计 Agent 系统的时候,很容易会进入误区:上下文越长越好,历史越多越好,检索越强越好。这个方向不能说错,但它很容易把“信息更多”误当成“系统更强”。问题恰恰出在这里。
第一,历史不是经验。一段失败日志、一轮工具调用、一次用户纠正,本身都只是原始轨迹。只有当系统把它提炼成“下次遇到类似情况该怎么做”,它才开始像经验。
第二,记忆不是能力。记住用户喜欢 TypeScript,只能算偏好;记住“这个项目部署前必须先跑某个脚本,不然生产环境会失败”,这才更接近可执行经验。前者让回答更像样,后者才会改变行动。
第三,上下文不是架构。把所有东西塞进 prompt,看起来像在增强系统,实际常常只是在推迟问题暴露。能长期跑下去的 Agent,必须分清哪些东西应该常驻,哪些只该按需找回,哪些适合沉淀成技能,哪些到了时间就该过期归档。
Hermes 的价值就在这里。它没有把“进化”寄托在模型自己变聪明这件事上,而是老老实实拆成了几个工程化子系统:Memory、Session Search、Skills、Curator、Tool Runtime、Context Compression、Gateway/Platform Layer。这些模块组合起来以后,“越用越强”才不再只是一个漂亮说法,而开始像一套真能跑起来的架构。
二、先看 Hermes 怎么分流经验
Hermes 给我的启发,不是它有多少入口、多少工具,而是它没有把经验都塞进一个地方。
一次任务做完以后,Hermes 不会把所有东西都压成一段上下文摘要,而是把稳定事实提炼到 Memory,原始轨迹存储到 Session Search,成熟做法沉淀成 Skill,后面再交给 Curator 去治理。也因为这样,Hermes 的核心已经不是一个单纯的对话循环,而是一个会在执行后做经验分流的运行时。
后面几章看起来像是在讲 Memory、Session Search、Skills、Curator 这些分散模块,但它们其实都在回答同一个问题:一次执行结束以后,哪些东西该留下,留下以后又该放到哪里。
三、长期记忆要短,但要足够准
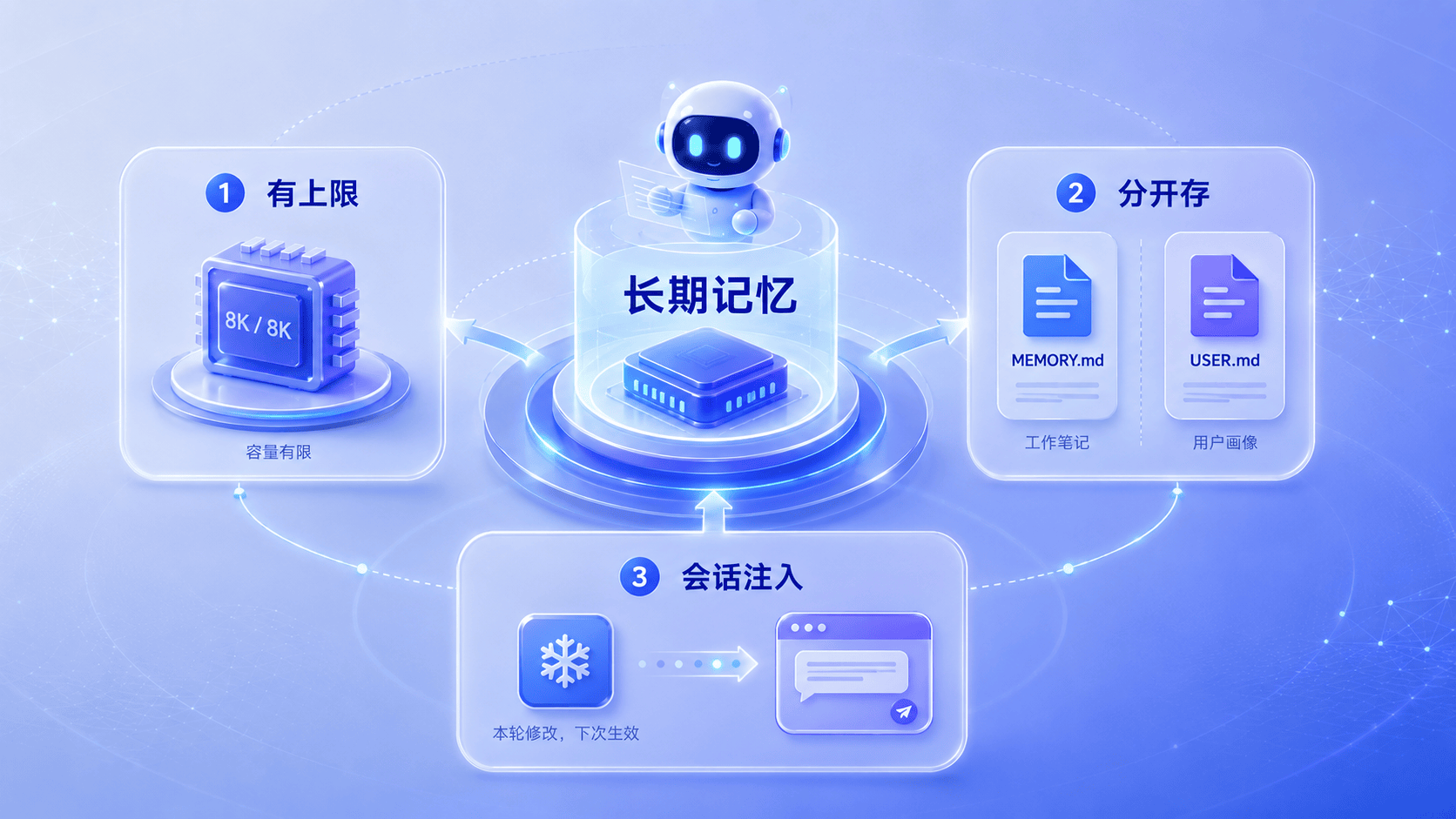
Hermes 的 Persistent Memory 不是无限记忆,而是一小块有边界、会被治理的长期记忆。它默认由两个文件组成:
MEMORY.md用于 Agent 自己的笔记,比如环境事实、项目约定、工具踩坑。USER.md用于用户画像,比如偏好、沟通风格和期望。
两者存储在 ~/.hermes/memories/,并在会话开始时作为冻结快照注入系统 prompt。
以下是 Hermes 在设计长期记忆时的几个重要原则:
设置字符上限
Hermes 对记忆设置了字符限制:MEMORY.md 默认约 2,200 字符,USER.md 默认约 1,375 字符。这个限制很有价值,因为它逼着系统承认一件事:不是所有内容都值得永久进入 prompt。
这比"无限向量库"更像真实工程。常驻记忆会影响每次推理,所以它必须短、准、稳定,不然系统很快就会被自己带偏。
Agent 的工作笔记和用户画像要分开放
MEMORY.md 更像 Agent 的工作笔记:项目路径、部署方式、工具坑点、已完成任务;USER.md 更像用户画像:沟通风格、技术水平、偏好。
这两个文件分开很有必要。"用户是谁"和"系统怎么做事"本来就是两类不同记忆,混在一起,prompt 很快就会变成一锅粥。
记忆快照在会话开始注入,本轮修改下次生效
Hermes 的记忆快照在会话开始时注入,之后即使本轮会话修改了记忆,也要到下次会话才会体现在系统 prompt 中。这么做不是保守,而是在“进化”和“稳定”之间做工程取舍。
可进化 Agent 并不意味着每一步都动态改系统提示词。很多时候,稳比快更重要。
四、原始轨迹别急着塞进 Memory

Hermes 没有把所有历史都压缩进 Memory。它还提供了 Session Search:所有 CLI 和 messaging session 会存进 SQLite,并用 FTS5 做全文搜索,检索结果再由 LLM 总结。Hermes 把 memory 和 session search 分得很清楚:
- Memory 适合关键事实常驻上下文。
- Session Search 适合按需找回过去讨论过的具体内容。
如果把 Agent 经验系统类比成人的工作方式,Memory 像“脑子里随时记得的原则”,Session Search 像“需要时可以翻的项目档案”。
一个成熟 Agent 不能只靠其中一个。只有 Memory,细节很容易丢;只有 Session Search,每次都得检索,成本高也不稳定。两者配起来,才像一个能长期工作的“常识层 + 档案层”。
五、自动把经验沉淀成技能,才是 Agent 进化的关键
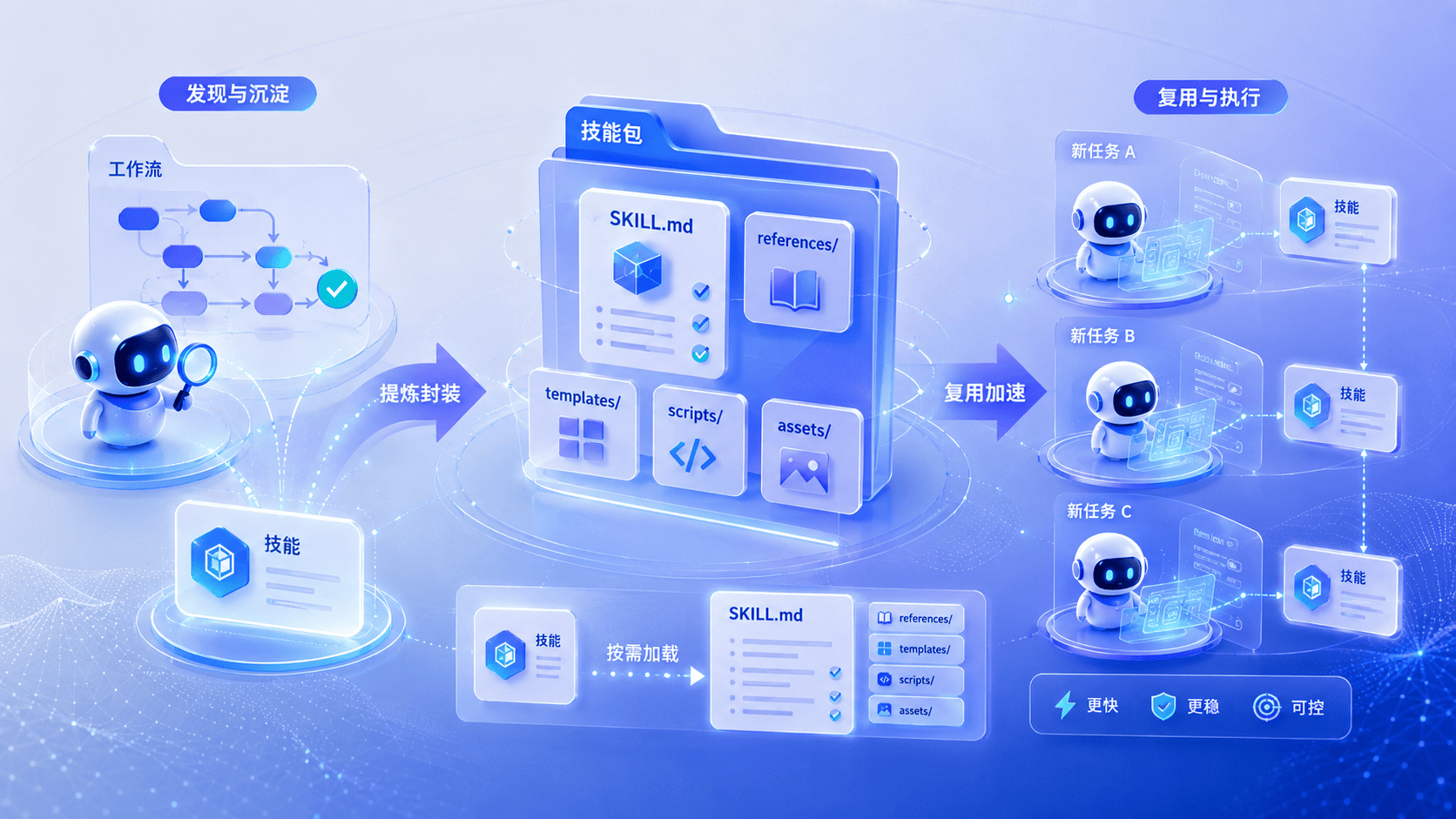
随着 Agent 系统越来越复杂,经验积累的价值也越来越大。每次成功完成一个多步骤的流程、经历了错误和修正或者用户纠正了做法,都是系统宝贵的经验。如果简单把这些经验当成事实写进 Memory,或者当成历史塞进 Session Search,系统很难真正复用它们。因为经验的价值不在于它曾经发生过,而在于它告诉系统“下次遇到类似情况该怎么做”。
Hermes 的方案是把经验封装成 Skill,而不是长期塞在 prompt 里。这里不只是多了一种知识组织格式,而是系统承认:有些经验根本不适合被写成一句事实,它天然就该长成步骤、约束、验收方式这样的结构。当 Hermes Agent 解决了一个有一定复杂度的多步流程时,可以把方法自动保存为未来复用的 skill。
Skill 和普通 RAG 不是一回事。RAG 是“把相关资料找回来”;Skill 是“把一套做事方法调出来”。前者的价值在于补信息,后者的价值在于定动作。
关于 Skill 的介绍可以看我之前写的这篇文章:跨越“知道”与“做到”:Agent Skills如何重塑AI的执行能力?。
这就是 Agent 从 “会回答” 走向 “会做事” 的分水岭。很多系统把经验积累理解成“把历史再喂回模型”,Hermes 往前多走了一步:它开始把任务结果改写成未来的行为结构。
六、经验治理是必须的,否则系统会被自己拖垮
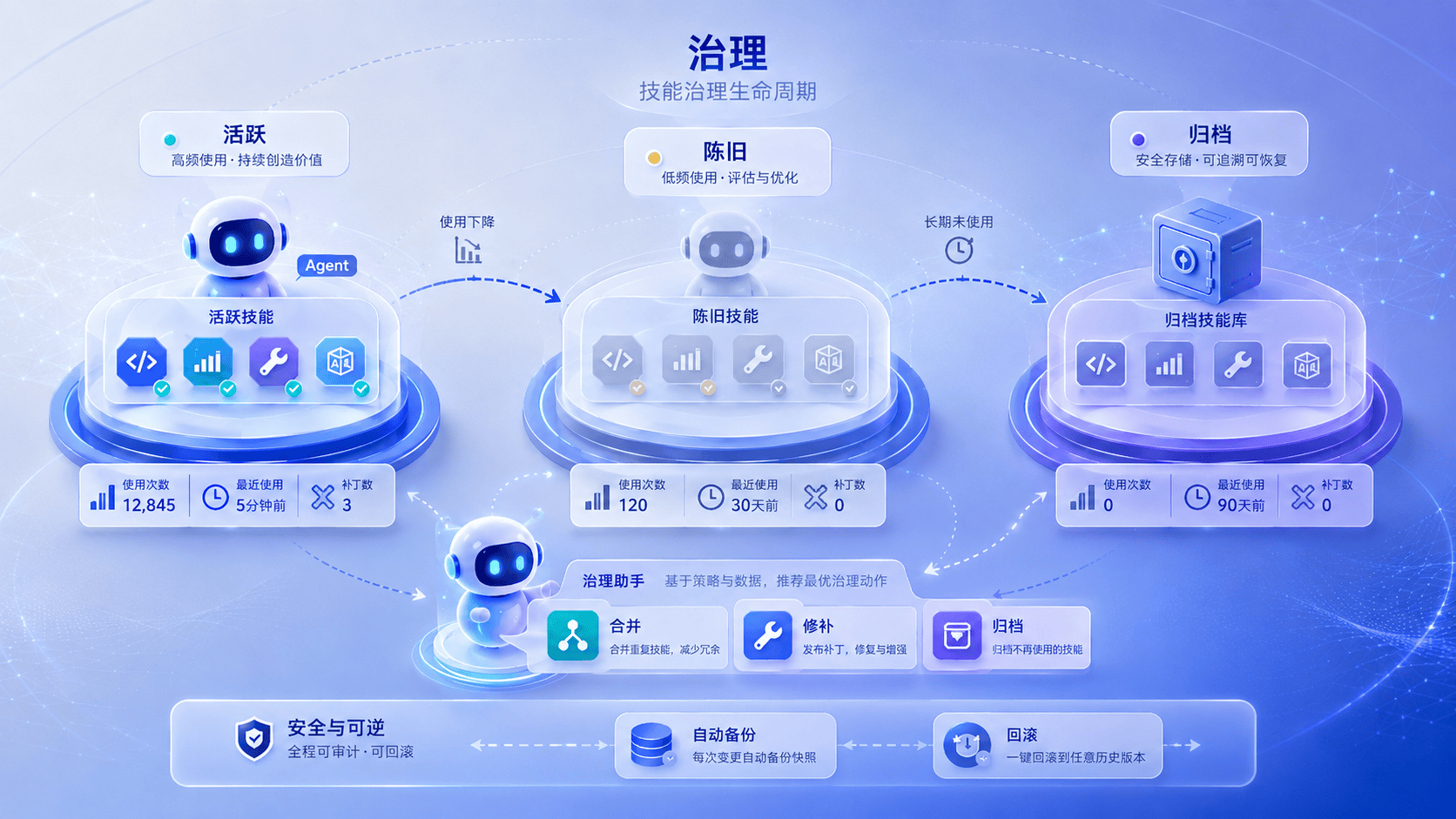
很多团队一谈 Agent 进化,先盯住的都是写入:怎么把成功路径变成 Skill,怎么把用户纠正写进记忆,怎么让系统越用越懂项目。但系统一旦真的开始积累经验,更麻烦的问题很快就会冒出来:旧经验不会自己退休,重复经验不会自己合并,错误经验也不会自己消失。
一个 Agent 每次成功都写一个 Skill,短期看像在变强;时间一长,系统更可能被另一种成本反噬:目录里堆满相似但不完全相同的做法,有的对应旧流程,有的只在某个临时环境里成立,有的早就被后来的技能覆盖。到这一步,Skill 不再只是资产,也开始变成噪音,抢上下文、干扰选择、污染判断。
Hermes 为此设计了 Curator。你可以把它理解成一个专门治理 Agent-created skills 的后台流程:系统会跟踪每个技能被查看、使用和 patch 的频率,把长期不用的技能从 active 移到 stale,再到 archived;同时周期性触发辅助模型做 review,提出合并、修补或归档建议。
我更看重 Curator 的,不是它用了哪些字段,而是它把一件常被忽略的事摆到了台面上:经验系统的麻烦,从来不只是怎么积累,还有怎么对抗熵增。 很多人做 Agent 记忆时,只考虑“怎么写入”,不考虑“怎么淘汰”。但只要系统开始进化,流程变化、技能冲突、局部经验过时这些问题迟早都会撞上来。
Hermes 的 Curator 设计遵循以下原则:
技能要有状态
技能不是永久有效的,它应该有状态,Hermes 定义了 active、stale、archived 三个状态:
active: 新技能或最近被用过的技能active --> stale: 长期低频或不再匹配当前流程stale --> archived: 持续未使用且可被替代
基于有状态的经验技能,系统才能区分 “当前推荐使用的经验” 和 “历史上曾经有用的经验”。这两者看起来只差一点措辞,工程含义却完全不同。前者应该优先暴露给 Agent,后者更适合降权、归档,或者只在特定条件下找回。治理层一旦缺位,这两类经验就会被混在一起,最后让 Agent 在旧答案和新流程之间来回摇摆。
用使用频率说话,不靠感觉判断
Curator 会维护每个技能的 use_count、view_count、patch_count、last_used_at、last_patched_at 等指标。
这意味着经验治理不是凭感觉,而是基于使用痕迹。该保留的经验,不一定是“写得很完整”的经验,而是“持续被用、被修、还能适配当前流程”的经验。对运行中的 Agent 来说,还在不在被使用,比当初写得多漂亮更重要。
经验修改要能撤回
Curator 在真实执行前会做备份,支持 rollback 和 restore。
这是生产系统非常需要的设计。Agent 自我改进不能变成不可逆自我破坏。经验治理动的是系统未来的行为边界,没有回滚能力,所谓“自动优化”很容易变成一次悄无声息的错误发布。
总之,Curator 解决的不是 “技能太多看着乱” 这种表面问题,而是更根本的运行问题:如果没有治理层,系统最后会被自己的存量经验拖垮。 通过状态管理、数据驱动的决策和安全回滚,Curator 让经验系统不只是会积累,还能持续保持健康的能力边界。
七、长任务:经验最丰富,也最容易失忆
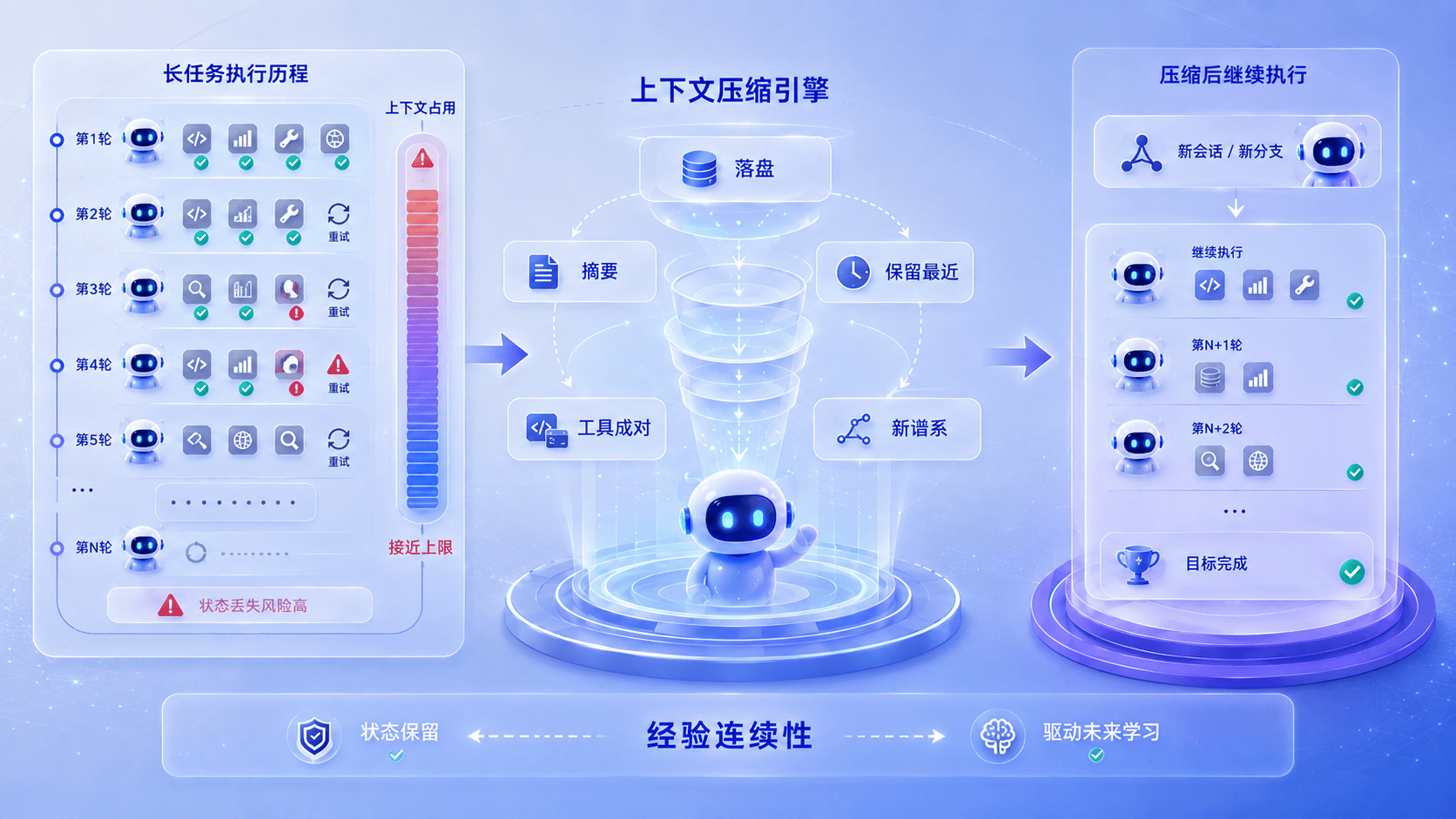
可进化 Agent 有一个内在矛盾:越复杂、越多轮的任务,往往越有沉淀价值,也越容易把系统推到上下文极限。一次简单查询不需要经验积累,真正值得固化成记忆或技能的,往往是那种跨越多轮、反复出错、最终找到解法的复杂任务。但偏偏就是这类任务,最容易把上下文撑爆。
一旦系统在长任务里开始丢状态、断轨迹,前面谈的记忆、技能、治理都会失去稳定的输入来源。 这不是"上下文不够用"的成本问题,而是经验系统最脆弱的那一环——能不能跨过去,决定了系统沉淀的是"短对话技巧",还是"复杂工作方法"。
Hermes 的解法是上下文压缩。当会话超过模型上下文窗口的 50% 时,会触发 preflight compression;Gateway 场景下超过 85% 则会更激进地自动压缩。压缩不是简单删历史,而是一套有优先级的重组策略:
- Memory 先 flush 到磁盘,保证稳定事实不随压缩丢失
- 中间轮次被总结压缩,降低 token 占用
- 最后 N 条消息保留原文,保证当前任务不断线
- 工具调用和结果成对保留,确保执行轨迹可以回放
- 生成新的 session lineage,记录任务的演化路径
其中两点设计原则很有启发:
- Memory flush 的优先级高于压缩本身,说明系统把经验持久化看得比上下文管理更重要。
- 工具调用和结果必须成对——单独保留任意一边,都会把经验切断成无法复盘的碎片:你只知道"做了什么",却不知道"发生了什么",或者反过来。
所以压缩层并不是在和经验系统抢资源,它本身就是经验得以延续的基础设施。没有这层,系统只能在短链路里成长;一遇到真正复杂、有沉淀价值的任务,反而最容易失忆。
八、如何更好的设计可进化 Agent 的架构
Hermes 给我的启发,不是某个单点功能,而是它把经验拆开处理。稳定事实、历史轨迹、可复用流程、治理信息,本来就不是一类东西。如果都塞进一个“记忆模块”,系统很快会变成一团难以判断权重的上下文。
我更愿意把它抽象成四层:
- 记忆与检索层:决定什么常驻上下文,什么按需找回。
- 技能与治理层:决定什么沉淀成流程,什么降级或归档。
- 行动执行层:留下可复盘、可学习的执行轨迹。
- 连续性保障层:让长任务不因为上下文截断而丢掉经验。
对应到 Hermes,大致是这张图:
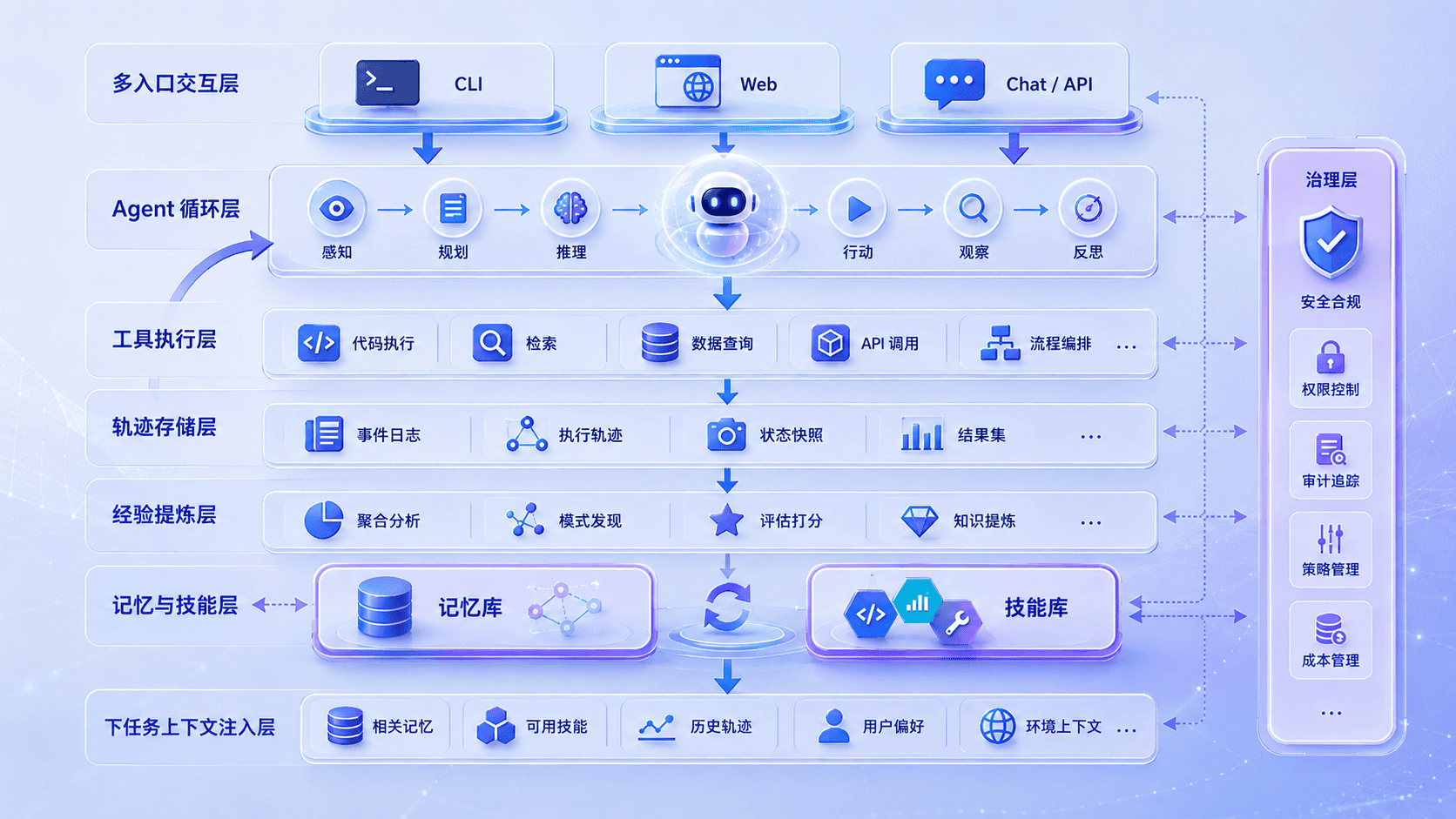
这里真正重要的是分工:Memory 只放少量稳定事实;Session Search 存完整历史;Skill 承接可复用流程;Curator 管生命周期;Tool Runtime 产生可审计的行动记录;Compression 保住长任务里的连续性。
换句话说,Hermes 不是在问“怎么让 Agent 记住更多”,而是在问三个更工程化的问题:什么经验该留下,以什么形状存在,怎样安全地影响未来行为。 这三个问题拆开以后,“越用越强”才不再只是一个口号。
九、总结

Hermes 最打动我的地方,不是它接了多少工具,也不是它支持多少入口,而是它把一件事想清楚了:Agent 不是做完一次任务就结束。只要它还会继续工作,就应该从已经做过的事情里学到一点东西。
一次任务里,Agent 会看到用户的目标,会调用工具,会遇到错误,也可能被用户纠正。普通系统往往只把这些东西留在聊天记录里,下一次能不能想起来全靠运气。Hermes 的做法更像一个认真复盘的工程师:哪些事实以后还会用,就放进 Memory;哪些过程需要回看,就放进 Session Search;哪些步骤可以复用,就做成 Skill;哪些 Skill 过时了,就交给 Curator 清理。
所以我现在在设计 Agent 系统的进化能力时,不会只看“能不能记住更多”,而会更加关注:
- 它做过的事,下次如何能派上用场?
- 它犯过的错,下次如何能少犯一次?
- 用户纠正过它,如何做的更像个听话的学生,而不是一个死记硬背的机器人?
- 一条成功经验写进去以后,如何能更新、回滚、查来源?
这些点看起来都是细节,但它们的工程含义却完全不同。一个真正可进化的 Agent,不是把经验当成“更多信息”,而是把经验当成“未来能力”。只有当系统在设计上承认了这个区别,才有可能真正跑出一个越用越强的 Agent 来。
当然,不是所有 Agent 都需要做成这样。如果只是一次性问答、短流程助手,或者任务之间几乎没有复用价值,Memory、Skills、Curator、Compression 全部堆上去,复杂度可能超过收益。
这套架构真正适合的,是那些会跨会话、跨任务、长期运行,并且反复处理相似工作流的 Agent。比如研发助手、运维助手、数据分析助手、企业内部流程助手,它们每天都在做相似但又不完全一样的事。对这类系统来说,经验如果不能沉淀,就会不断重复踩坑;经验如果没有治理,又会慢慢变成噪音。
最后,我觉得可进化 Agent 的核心挑战,不是技术细节,而是设计哲学:我们是想做一个会话系统,还是一个会成长的 Agent? 前者可能只需要把信息塞进上下文;后者则需要把经验拆开处理,让它真正成为系统未来能力的基石。
参考资料
Continue your reading
When you finish this article, use these paths to continue the thread.
// tags
Explore adjacent topics and move sideways through the knowledge graph.