跨越“知道”与“做到”:Agent Skills如何重塑AI的执行能力?
Abstract
当 AI 从聊天工具走向 Copilot 和 Agent,真正卡住交付质量的,往往不是模型本身,而是缺少一套能重复、能维护、也能沉淀经验的执行路径。本文从 Agent Skills 的定义、工作机制、与 MCP 的关系以及落地方式出发,解释为什么 Skill 正在变成 Agent 系统里的能力封装层。
Jump to section
目录
- 为什么 Agent 开始需要 Skills 这层封装?
- 为什么纯 LLM 总卡在”知道”和”做到”之间?
- 先说清楚,Agent Skill 到底是什么?
- 为什么 Skill 比”超长 Prompt”更像工程方案?
- MCP、Function Calling 和 Skills,到底差在哪?
- 一个 Skill,拆开来看长什么样?
- 拿一个真实案例看,Skill 怎么把工作流收成能力?
- 对团队来说,什么东西最值得做成 Skill?
- 1. 高频重复的执行流程
- 2. 团队内部的隐性知识
- 3. 需要确定性执行的动作
- Skill 真要落地,最容易踩的三个坑
- 安全边界
- 维护成本
- 触发设计
- 最后想说:Skill 真正沉淀的是”做事的方法”
- 开源项目
- 参考资料

这两年 AI 产品形态换得挺快的。最早大家聊 Chatbot,看的是它能不能答上话;后来出了 Copilot,看的是它能不能在具体软件里帮人干活;再往后到了 Agent,标准又变了,变成它能不能自己理解目标、拆解步骤、把事情真做完。
光看产品形态,这像是一条自然的升级线。但落到工程上,问题就没那么简单了。真正卡住系统的,往往不是模型会不会说话,而是整个系统有没有办法把一件事稳定地做完。
所以今天再聊 Agent Skills,如果还停留在“这是 Anthropic 推出的一个新格式”这个层面,焦点已经偏了。更值得想的问题是:AI 已经进到开发、内容生产、研究、部署和企业工作流里了,那些经验、团队约定、外部工具和执行路径,到底该怎么交给 Agent 长期复用?
我的看法是,Agent Skill 的价值不是给 Prompt 包层壳,而是把知识和执行方式封成 Agent 能按需调用的能力单元。
为什么 Agent 开始需要 Skills 这层封装?
如果只把 LLM 当问答工具,很多问题还没那么明显。模型会总结、会解释、会改写,偶尔跑偏一点,人类大多也能兜住。但一旦把它放进真实工作流,考核标准就完全不一样了——你关心的已经不是它”知不知道”,而是它”能不能稳定地做对”。
AI 交互形态的变化,表面上是产品在迭代,实际上是责任边界在转移。Chatbot 主要负责生成文本,Copilot 在局部场景里协作,Agent 则开始承担更完整的执行责任。能力越往后走,系统就越依赖结构化知识、可重复的流程和清晰的工具边界。
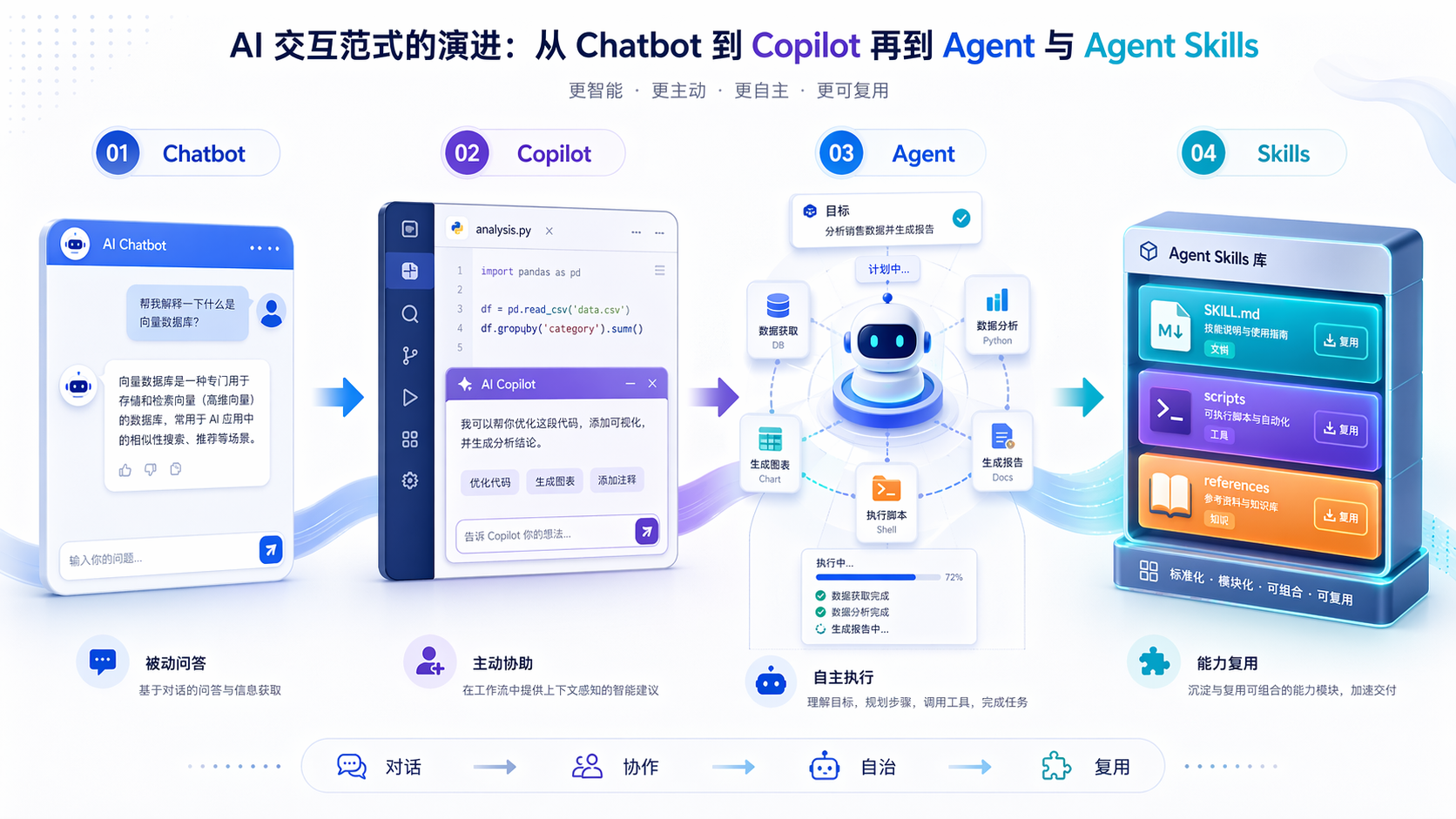
说白了,”让 AI 拥有双手”比”让 AI 更会说话”更重要。真正卡住 Agent 的,往往不是少了一句更精妙的提示词,而是少了一套能反复复用的做事方法。
为什么纯 LLM 总卡在”知道”和”做到”之间?
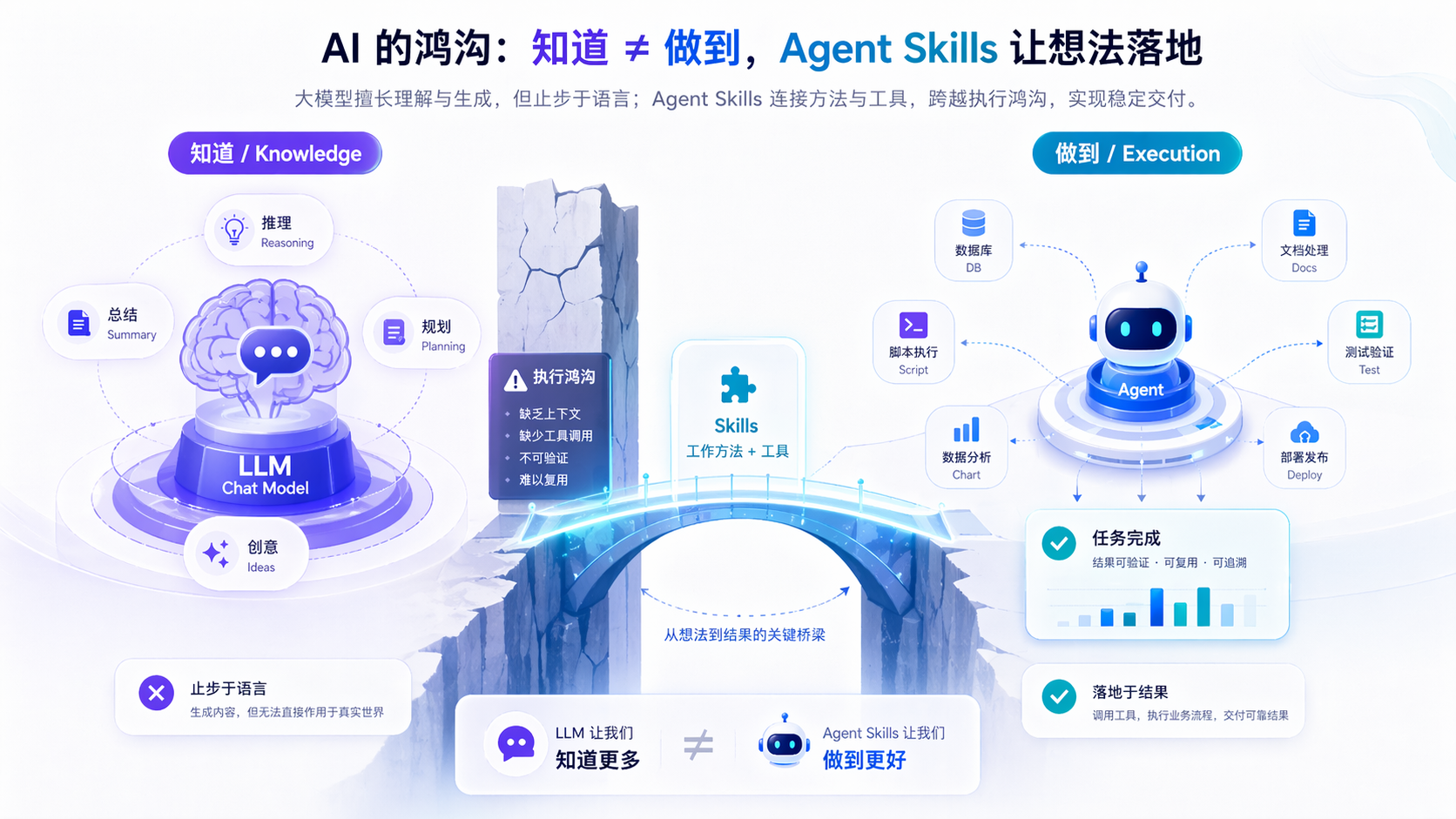
纯模型系统的问题不难理解。它会幻觉,对实时世界的认知总是滞后的,而且关键在于——它本身没有行动能力。你可以让它规划出”先查数据、再生成图表、再发邮件通知团队”的步骤,但系统里如果没有可靠的执行路径,这些步骤就还是停在嘴上。
简单问答里这个问题不大,到了真实任务就会被放大。研发助手不知道项目的工程约定,就会一遍遍生成不符合团队偏好的代码;内容助手不清楚发布流程,就会每次都重新摸索模板、格式和上传步骤;企业内部 Agent 如果不知道审批、文档、工单系统之间怎么协作,即便接了很多 API,也未必能稳定跑通一条完整流程。
所以问题从来不只是 ”模型能不能调工具”,而是 ”模型手里有没有一套适合这类任务的做事方法”。Agent Skills 想补的,正是这一层。
先说清楚,Agent Skill 到底是什么?
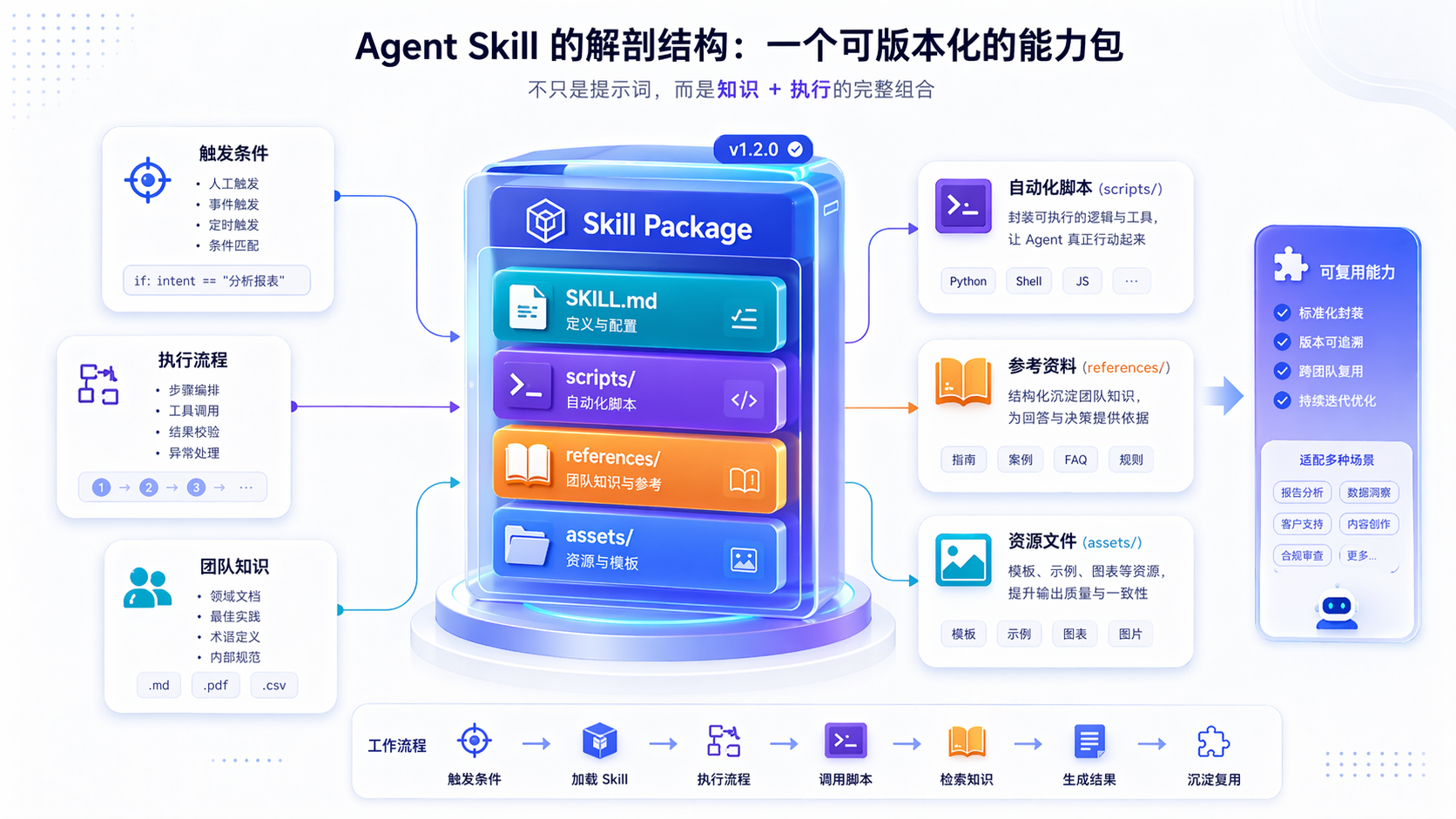
Anthropic 在 2025 年 10 月公开介绍的定义里,Skill 本质上是一个目录,至少包含一个 SKILL.md,也可以带脚本、参考资料、模板和其他资源。到 2025 年 12 月,这套格式被推进成跨平台开放标准,目标不再只是服务某一个产品,而是让更多兼容 Skill 的 Agent 客户端都能复用同一套能力包。
说白了,Skill 既不是某个函数,也不是某个插件入口,它更像一个可版本化的能力包。通常会放三类东西:
| 组成部分 | 作用 | 解决的问题 |
|---|---|---|
指令 SKILL.md | 告诉 Agent 该怎么做、何时触发、优先遵循什么规则 | 让流程不再依赖临时 Prompt |
脚本 scripts/ | 放置可执行的 Python、JS、Shell 等代码 | 把高频重复动作变成确定性执行 |
参考资料 references/ / 资源文件 | 放置 SOP、API 说明、模板、配置、素材 | 把团队知识和上下文从对话里剥离出来 |
这三样东西叠在一起,Skill 才真正变成 ”知识 + 能力” 的封装。它不是只告诉 Agent 一个抽象概念,而是在说:遇到这类任务,该沿什么路径做;哪些动作该交给脚本;哪些细节该去翻参考资料。
与其说 Skill 是给 Prompt 加了点什么,不如说它更像给 Agent 的一份”岗位入职包”——告诉它该怎么做,而不是每次都临时说明。
为什么 Skill 比”超长 Prompt”更像工程方案?
很多团队刚开始做 Agent 时,最顺手的办法往往是把流程、约束、注意事项、示例和边界条件统统塞进 system prompt。前面它确实能跑,但任务类型一多,问题就越来越明显。
最直接的问题就是 context 膨胀。很多说明只对某一类任务有用,却要在所有对话里反复占 token。再往后,流程、资源、模板和脚本都混在 prompt 里,版本管理做不了,code review 也难,边界越来越糊。

Skill 更像工程方案,核心不是用了 Markdown,而是把这些东西分了层。开放标准和 Anthropic 官方文章都在强调一个关键词:progressive disclosure。先只暴露少量元信息,让 Agent 知道”这里有一项能力”;只有任务真的命中时,才去读完整的 SKILL.md,再按需读参考资料或执行脚本。
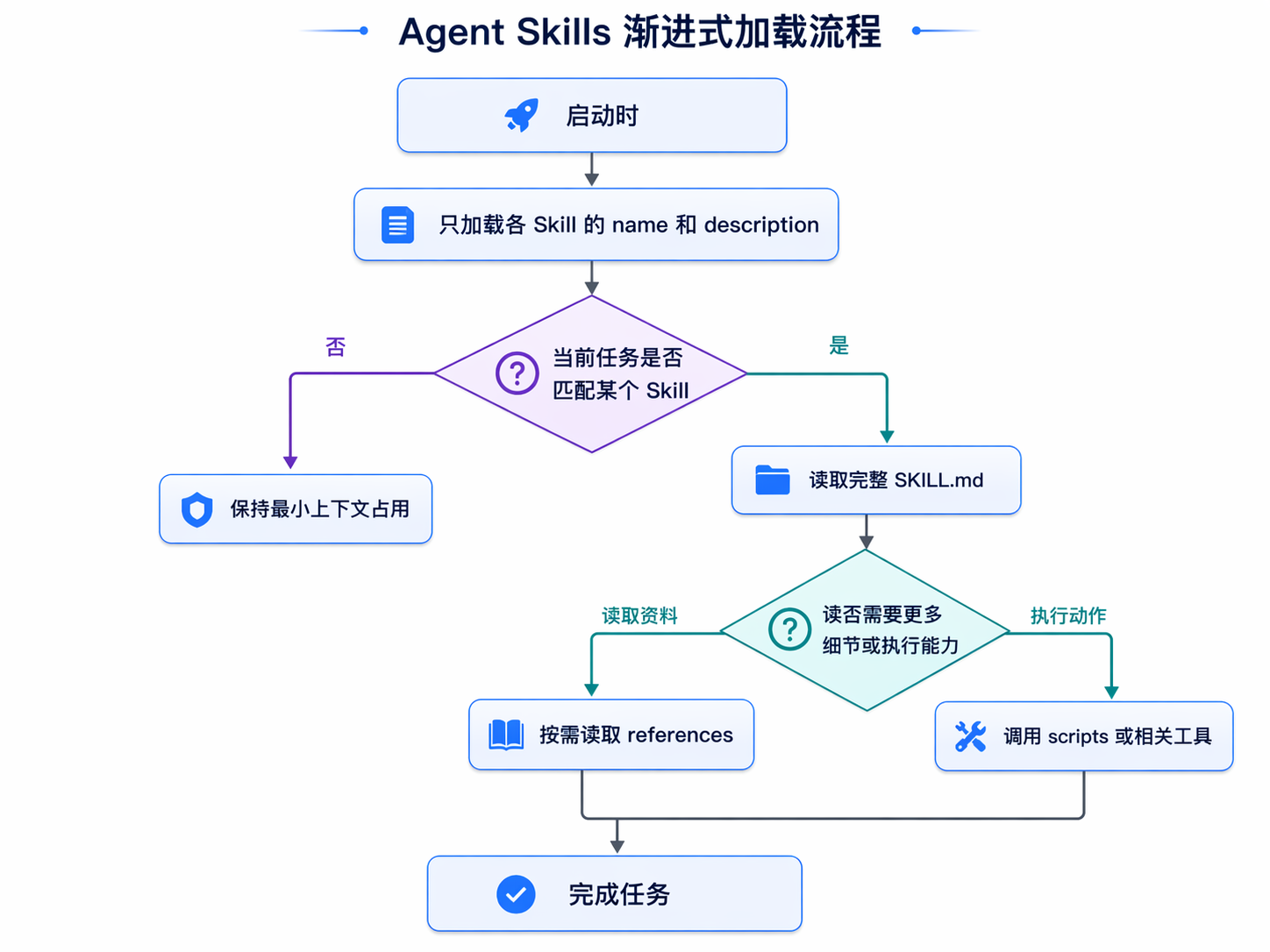
这个机制解决的是上下文成本和执行边界的问题。相比把所有内容一次性塞进 prompt,Skill 把 触发信息、核心流程、细节资料 和 可执行代码 拆到了不同层级。这样 Agent 可以挂很多能力,但不需要每次对话都把全部细节背进 context。
MCP、Function Calling 和 Skills,到底差在哪?
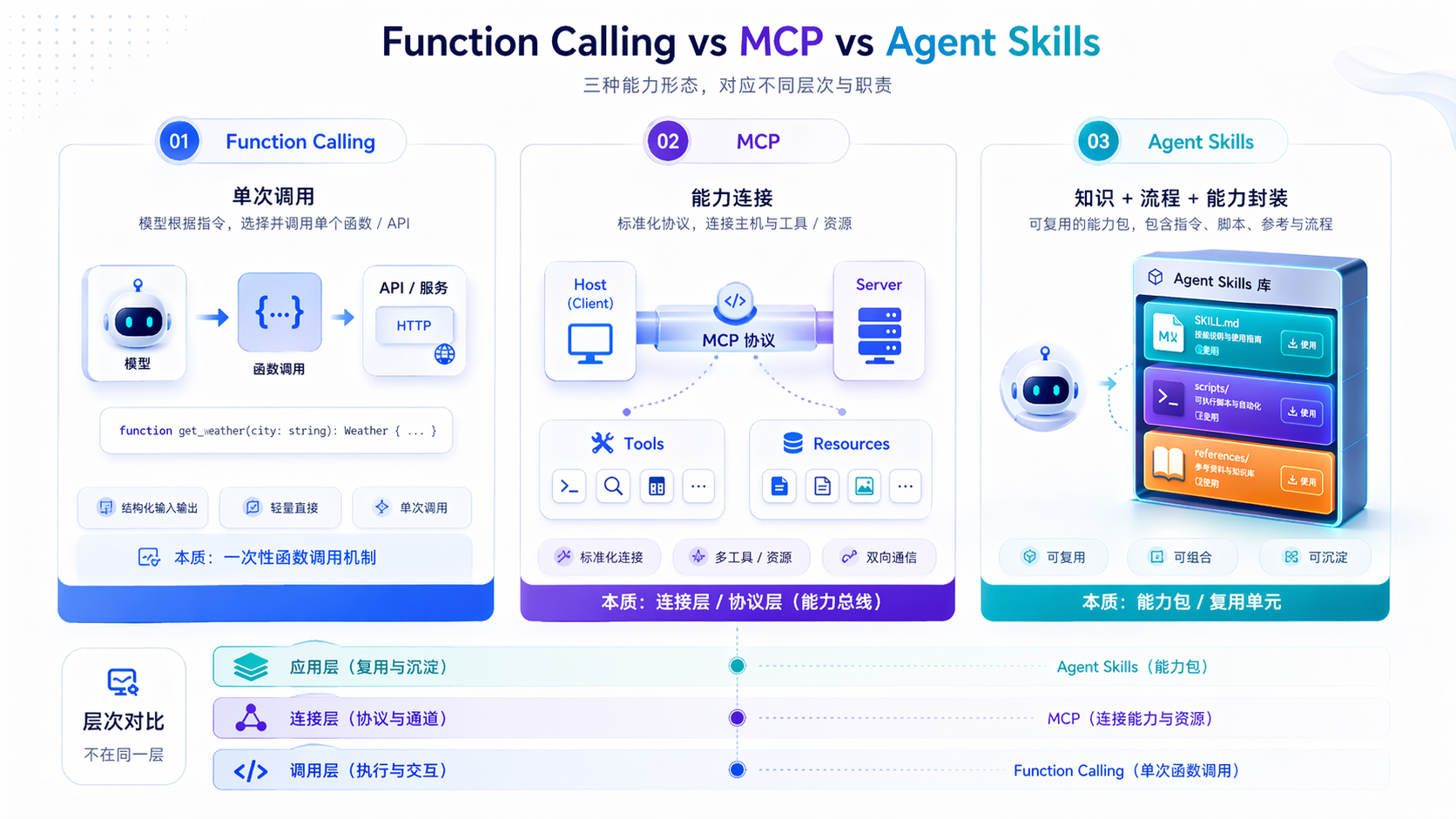
聊 Agent Skills 时,常会把它和 MCP 或 Function Calling 放在同一层来比较。其实它们解决的问题并不相同。
Function Calling 关心的是模型如何按 schema 调用某个函数。MCP 关心的是宿主怎么把外部工具、资源和服务以标准协议接进来。Skill 关心的则是,Agent 在面对某类任务时,该沿什么工作流、借助哪些资源和脚本把事做对。
| 维度 | Function Calling | MCP | Agent Skills |
|---|---|---|---|
| 关注重点 | 单次函数调用 | 外部能力连接与传输 | 知识、流程与能力打包 |
| 主要对象 | 模型输出接口 | Host / Client / Server 之间的协议 | Agent 任务执行方式 |
| 核心产物 | 函数 schema | 协议化工具与资源接入 | SKILL.md、脚本、参考资料 |
| 解决的问题 | 会不会调 | 连不连得上 | 做不做得稳、能不能复用 |
| 更像什么 | 调用机制 | 连接层 | 能力封装层 |
所以拿 Skills 和 MCP 对打没什么意义,两者根本不在同一层。MCP 解决的是能力怎么接进来,Skill 解决的是这些能力接进来以后怎么组织、怎么在具体任务里用对。前者像接口规范,后者像工作方法。
Model Context Protocol 官方文档里已经有了 “Build with Agent Skills” 这样的页面,方向已经说得很明白了:连接能力的标准化和使用能力的标准化,最后会汇到同一套 Agent 工程方法里。
一个 Skill,拆开来看长什么样?
落到文件结构上,Skill 的门槛其实不高。以官方仓库里的 pdf Skill 为例,结构大概是这样的:
pdf/
├── SKILL.md
├── scripts/
│ ├── add_annotations.py
│ ├── check_form_fields.py
│ ├── extract_form_structure.py
│ ├── read.py
│ └── ...
├── references/
│ ├── FORMS.md
│ └── REFERENCE.md
└── assets/
对应的 SKILL.md 里会先定义触发边界,再给出不同任务的处理路径:
---
name: pdf
description: Read, extract, merge, split, rotate, create, fill, or OCR PDF files.
---
## 读取 PDF
优先使用 `scripts/read.py`,它会处理分页和编码问题。
## 处理表单
需要先运行 `scripts/check_form_fields.py` 检查是否存在可填写字段,
再通过 `scripts/extract_form_structure.py` 提取表单结构。
## OCR 处理
读取 `references/REFERENCE.md` 了解具体的 OCR 流程和依赖。
## 旋转、合并、拆分
查看 `references/FORMS.md` 获取不同场景的处理方式。
重点不在 Markdown 本身,而在于它把触发条件、任务路由和执行脚本都绑在了一起。name 和 description 负责被发现,正文告诉 Agent 怎么走流程,脚本和参考资料负责把那些高频、易错、最好别靠模型临场发挥的部分收住。
做到这一步,它就不是”写给模型看的说明”了,而更像一个有边界的工程接口。
拿一个真实案例看,Skill 怎么把工作流收成能力?
光讲定义容易写虚。要看清楚 Skill 到底解决什么问题,还是得看真实仓库怎么落地。
看 anthropics/skills: https://github.com/anthropics/skills 这个官方仓库会比较直观。它的重点不是”给 Claude 多准备几条提示词”,而是展示 Skills 这套东西能承载多复杂的能力封装。README 里提到的范围很广,从创意任务、技术任务到企业工作流,再到 docx、pdf、pptx、xlsx 这类更重的文档能力,都已经放进去了。它既是示例仓库,也是在展示一套接近生产环境的 Skill 组织方式。
拿其中最典型的 pdf Skill 来看,会更容易理解 Skill 为什么不是普通 Prompt。这个 Skill 的 frontmatter 先定义了非常明确的触发边界:只要用户要读取、提取、合并、拆分、旋转、创建、填写或 OCR PDF,都应该触发它。正文再给出不同任务的处理路径,进一步把复杂操作拆到 FORMS.md、REFERENCE.md 和具体脚本里。仓库里有检查是否存在可填写字段、提取表单结构等脚本,用来支撑更稳定的 PDF 处理流程。
把这条链路画出来,会更容易看清 Skill 的作用:
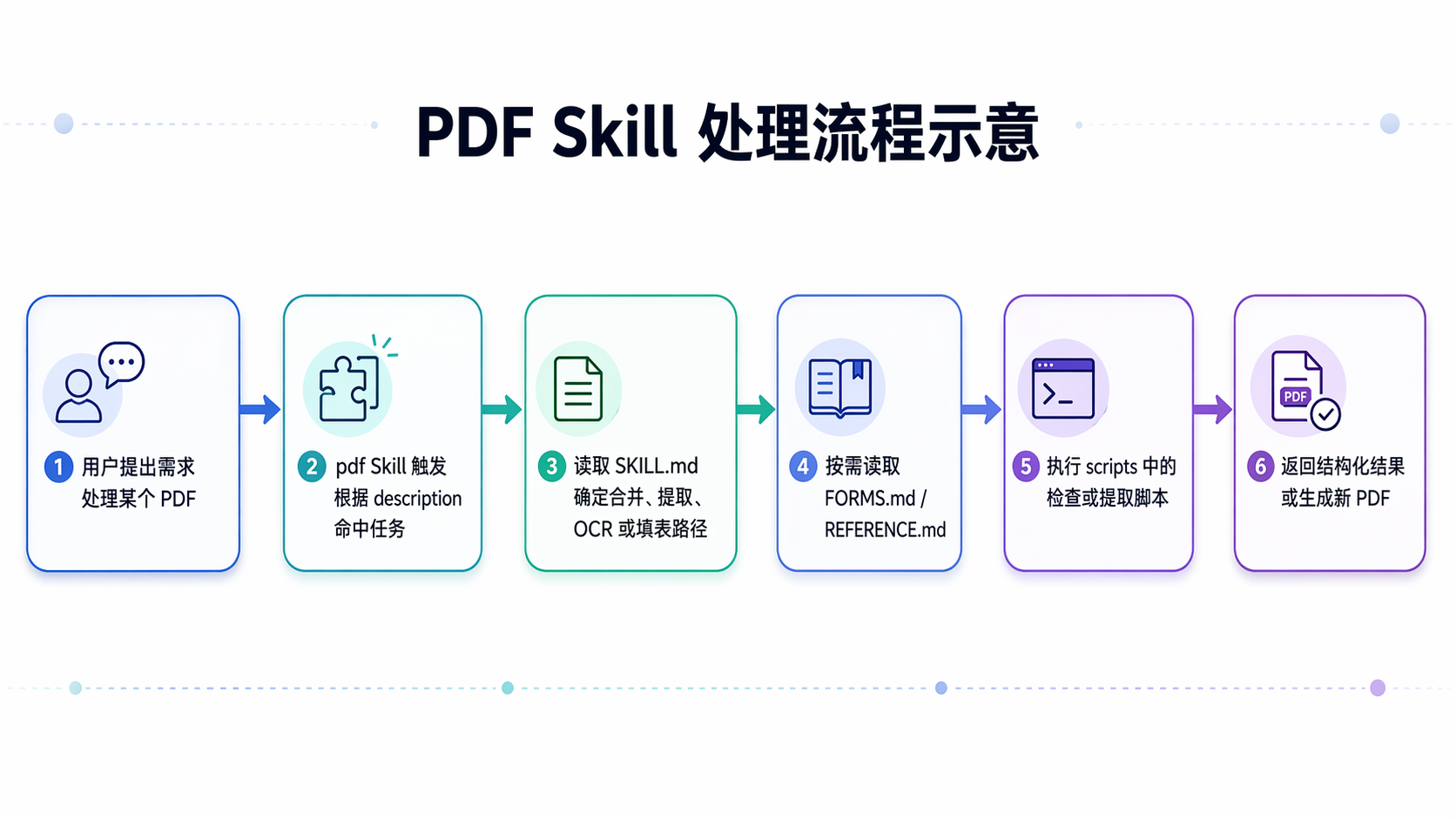
这条流程值得看,不是因为”处理 PDF”这件事有多新鲜,而是因为它把 Skill 的作用边界画得很清楚。Skill 不替代底层协议,也不替代工具本身,它做的是把一个高频、规则明确、细节又多的任务域,整理成可发现、可加载、可执行、可维护的能力包。
Anthropic 把这类 Skill 公开出来,真正有价值的地方也在这里——让人看到复杂 Skill 从来不是多写几条提示词,而是把触发逻辑、任务路由、扩展资料和确定性脚本一起组织起来。
对团队来说,什么东西最值得做成 Skill?
那么,到底什么东西值得做成 Skill 呢?
我的看法是,别先从”我们能接哪些 API”开始想,那个起点容易把方向带偏。更合理的起点是反过来看:团队里哪些流程反复出现、经常出错,而且已经沉淀出一套稳定做法?这种东西才值得做成 Skill。通常就是下面三类。
1. 高频重复的执行流程
比如发布内容、生成周报、搭建前端项目、创建后端服务、导出 PDF、上传静态资源。这些工作本身不复杂,问题在于它们会反复出现。每次都从头口述一遍做法,很快就会变成纯重复劳动。Skill 最适合固定这种已经比较成熟的路径。
2. 团队内部的隐性知识
很多真正有用的经验并不写在公开文档里,而是藏在”这个团队平时就是这么干”的默认做法里。比如技术栈偏好、目录约定、代码审查规则、演示文稿风格、指标口径、对接流程。这些东西如果只存在少数人脑子里,组织迟早要为此付成本;把它们打包进 Skill 的参考资料和流程说明里,反而更靠谱。
3. 需要确定性执行的动作
Anthropic 官方文章特别强调了一点:有些操作就应该直接交给代码,而不是让模型用 token 去”演”。比如排序、文件处理、格式转换、接口调用、批量重命名、数据清洗。这正是 scripts/ 目录存在的意义。Skill 不只是把方法写下来,更重要的是把这些容易漂移的动作收进确定性的执行单元里。
Skill 真要落地,最容易踩的三个坑
Skill 听起来轻,做起来也不一定复杂,但绝不是没有代价。真往团队里推,有三件事得先想清楚。
安全边界
Skill 可以带代码、外部资源和执行指令,天然有安全风险。官方建议很明确:不要从不可信来源随便安装 Skill;如果来源不够可信,就先审查目录内容、代码依赖和外部网络访问路径。对企业团队来说,这意味着 Skill 仓库本身就应该纳入审计和评审流程,而不是当成一堆无害的 Markdown。
维护成本
把知识变成 Skill,不等于”一次写完,以后就自动生效”。工作流会变,工具会升级,脚本会失效,文档会过期。一个有价值的 Skill 仓库,本质上是一份要持续维护的能力目录,不是做完就能封存的 Prompt 收藏夹。
触发设计
很多 Skill 之所以不好用,不是因为内容不够多,而是因为 name 和 description 写得不准。Skill 能不能被触发,首先取决于它有没有把”自己解决什么问题、什么情况下该被用”说清楚。触发层一旦含糊,后面正文和脚本再完整,也很难真正进到执行链路里。
最后想说:Skill 真正沉淀的是”做事的方法”
如果只把 Agent Skills 理解成某个新格式,或者当成 Prompt Engineering 的一个变体,判断就会偏得很厉害。它真正重要的地方在于,把原本散落在聊天记录、个人经验、项目约定和零散脚本里的东西,收成了一个可发现、可加载、可组合、也更容易治理的能力单元。
对个人开发者来说,常用工作流终于不用再靠反复口述了;对团队来说,SOP、最佳实践和脚本第一次有了更像资产的承载方式;对整个 Agent 生态来说,它补上的是过去一直缺的那一层——我们不只需要标准化连接外部世界的协议,也需要标准化经验和执行方法本身。
所以真正决定一个 Agent 能不能稳定交付的,越来越不是它会不会说话,而是它手里有没有一套整理过、能按需加载、还能持续维护的做事方法。从这个角度看,Agent Skills 已经不是锦上添花,而是在 Agent 真正进入工作流之后,开始变成基础设施的一部分。
开源项目
基于 Karpathy LLM WIKI 设计思路,我整理成了一个开源项目,欢迎试用和贡献:LLM Wiki - GitHub
参考资料
Continue your reading
When you finish this article, use these paths to continue the thread.
// tags
Explore adjacent topics and move sideways through the knowledge graph.