Vibe Coding 不是偷懒:AI 编程正在改写工程控制权
Abstract
这篇文章从 Karpathy 对 Vibe Coding 的原始定义出发,结合 Addy Osmani 对 AI-Assisted Engineering 的区分、Claude Code 的 agentic coding 形态,以及 Stanford AI Index 2026 的数据,讨论 AI 编程为什么把工程重点从亲手实现推向定义约束、验证结果和承担后果。

当实现变得廉价,控制权开始变贵
Vibe Coding 这个词一开始有点像玩笑。Karpathy 描述的是一种近乎“放手”的开发体验:你把目标说出来,模型持续生成实现,你看结果、补反馈、改方向,甚至不用太关心每一行代码是怎么长出来的。
它会流行,不是因为定义严谨,而是因为很多开发者第一次用 coding agent 时,确实产生了同一种感觉:代码开始像一种可以被“调度”的材料,而不再只是必须逐行亲手完成的劳动。
但到 2026 年,Vibe Coding 已经不只是周末原型里的 “先跑起来再说”。它开始进入生产系统、团队流程、代码审查和事故复盘。词还是那个词,语境已经变了:当 AI 能够批量接管中间实现步骤时,团队交出去的到底是体力活,还是一部分工程判断?最后留下来的,又只是效率红利,还是更重的验收责任?
我更关心后一个问题。Vibe Coding 真正改写的,并不是“谁来敲键盘”,而是软件从需求到上线这条链路里,哪些控制点被上移了,哪些成本被推迟了,哪些责任没人能替你背。
它真正改写的,不是写代码,而是控制面
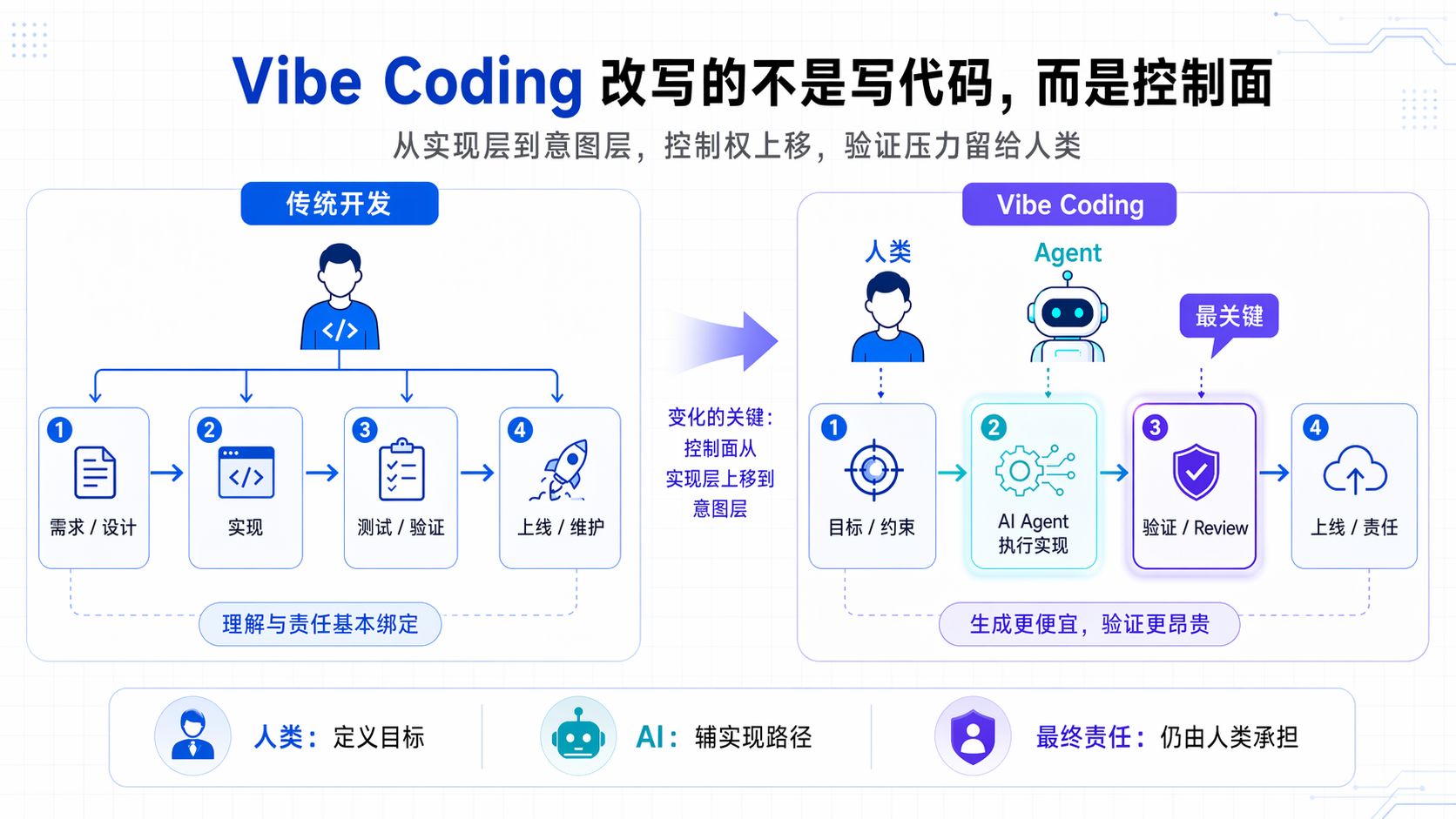
先把判断放在前面:Vibe Coding 的核心不是 AI 会不会写代码,而是人类把多少控制权从实现层挪到了意图层,同时把多少验证压力留给了自己。
传统开发里,需求、设计、实现、验证、上线大致还在同一条责任链上。你决定怎么拆模块,亲手写关键逻辑,也知道哪些边界条件最脆弱。系统出问题时,你未必马上修好,但通常知道先去哪儿翻。这个链条真正有价值的地方,不是慢,而是理解和责任一直绑在一起。
到了 Vibe Coding 语境下,中间执行链路被 AI 吃掉了一大块。你描述目标、补约束、看 diff、跑结果,它负责铺实现路径。于是人的角色从 “直接实现者” 变成了 “目标定义者、结果验收者和最终责任人”。代码是谁写的开始模糊,责任却不会因此变轻。
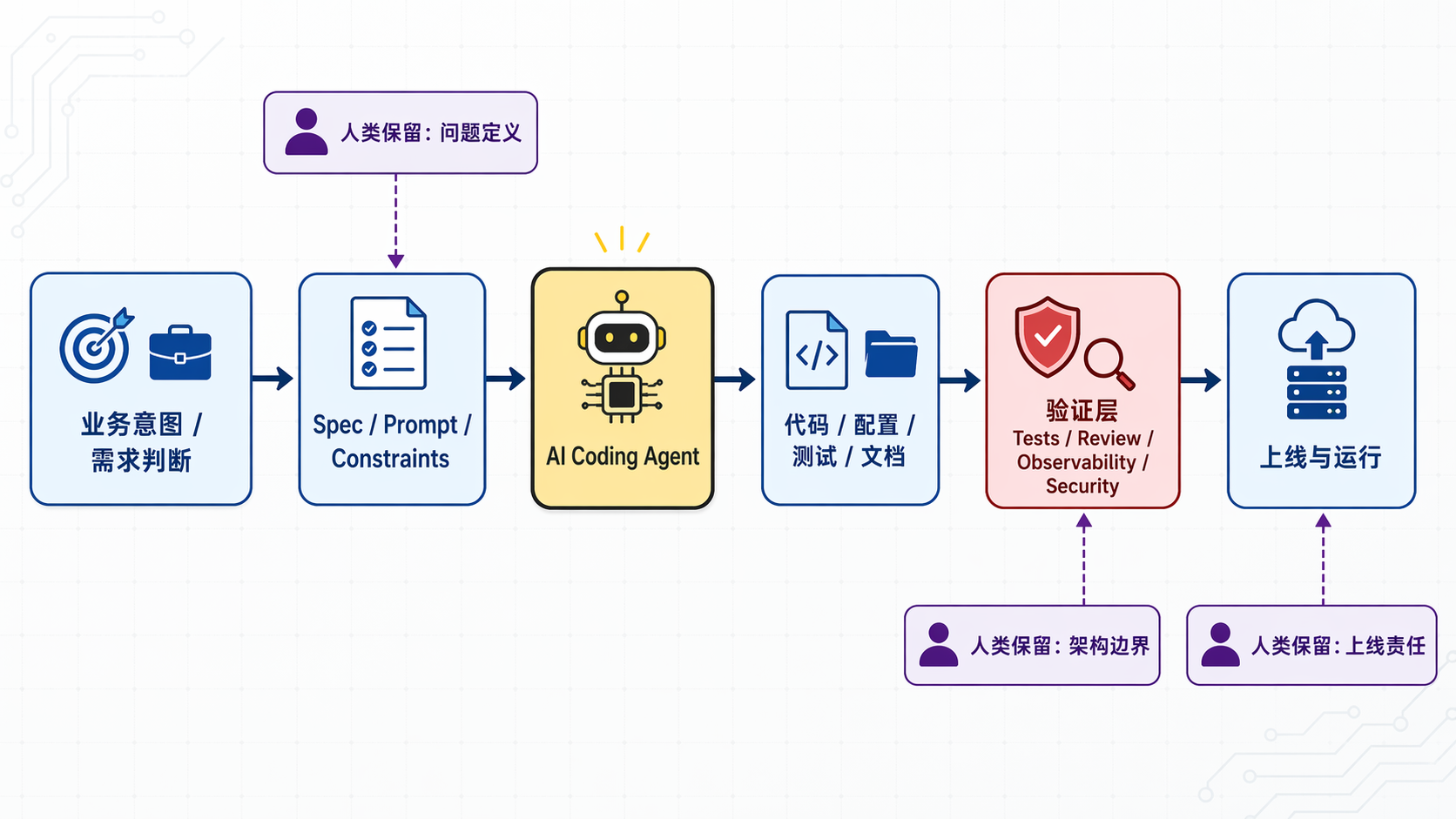
这张图里最值得看的不是中间的 agent,而是被单独拉出来的验证层。AI 让“ 做出一版 ” 变便宜了,但没有让 “证明这一版值得上线 ” 自动变便宜。以后真正稀缺的,可能不是生成能力,而是约束定义、审查精力,以及团队对系统还能不能说得清楚。
所以我不太赞成把 Vibe Coding 简化成“AI 写代码”。更准确地说,它是在把工程师的工作重心从实现层推向控制层。你写得少了,但你要对更多看不见的选择负责。
真正的分水岭,是你把哪段控制权交了出去
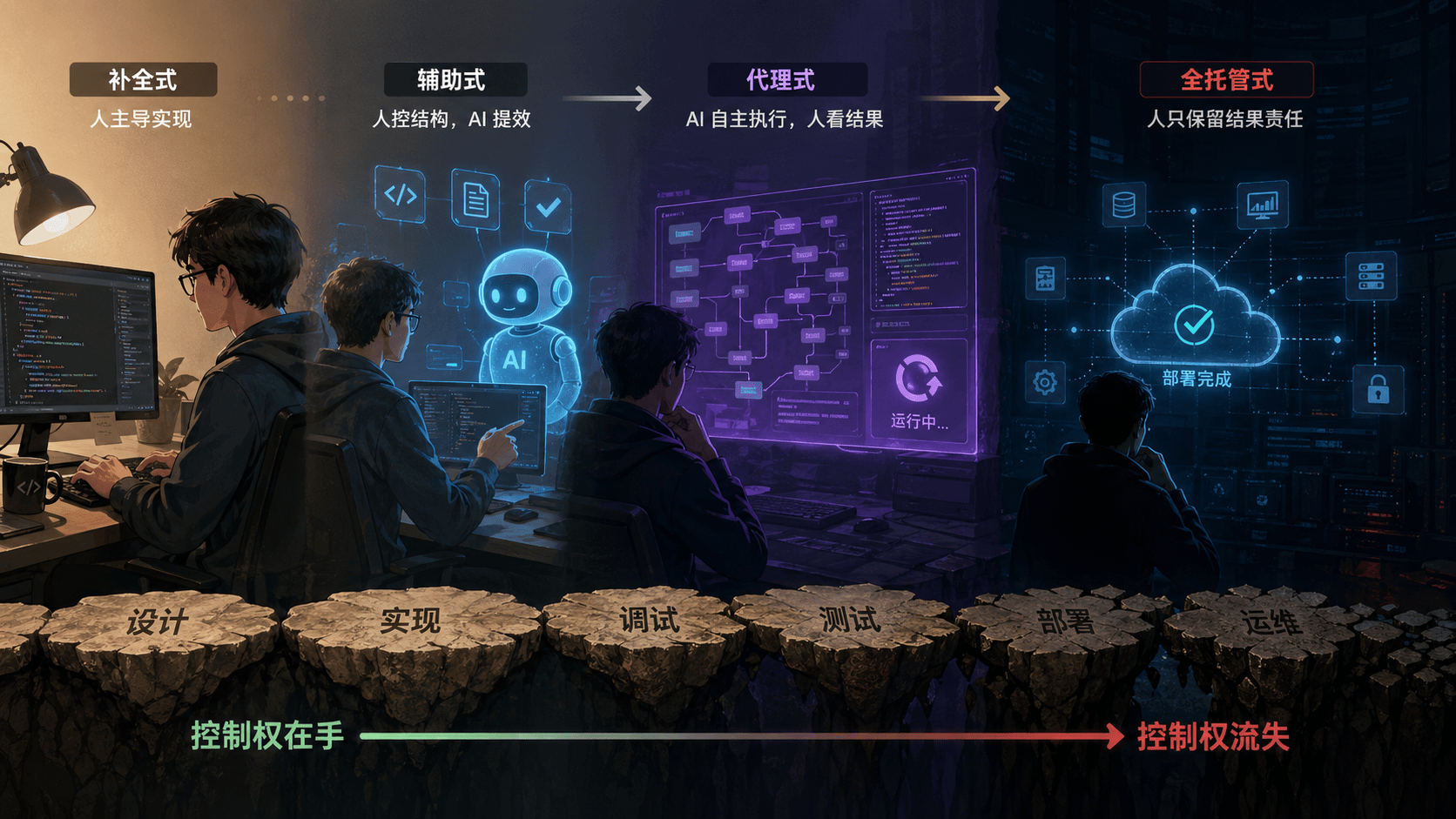
Karpathy 最初那段描述之所以传得开,是因为它抓住了一个新体验:开发者可以暂时“忘记代码本身”,主要靠语言和反馈驱动实现。这和早期 Copilot 式补全不是一回事。补全时代,AI 更像一个顺手的助手,你仍然主导结构、亲手处理关键路径;Vibe Coding 时代,AI 更像一个持续工作的执行体,人类很多时候只给目标和修正,不再逐层落实现细节。
麻烦也在这里:行业对这个词的用法已经漂移了。CodeRabbit 对术语演化的梳理很有代表性:它从“周末原型的放手式写法”,逐渐变成了“高强度、提示词驱动的 AI 编程实践”。一旦这些实践进入生产系统,Vibe Coding 讨论的就不再只是体验,而是质量、审查和事故。
所以,比起问“你有没有用 AI 编程”,更好的问题是:你到底把哪一段控制权交出去了?
| 模式 | 人类主要职责 | AI 主要职责 | 控制面特征 | 主要风险 |
|---|---|---|---|---|
| 补全式 | 设计、实现、Review | 局部补全、样板代码 | 实现路径仍在人手里 | 局部错误被顺手带过 |
| 辅助式 | 设计、拆任务、验收 | 生成模块、测试、文档 | 人控结构,AI 提高吞吐 | 看似懂了,其实理解变浅 |
| 代理式 | 给目标、给约束、看结果 | 多步修改、运行命令、迭代修复 | 中间执行链路开始黑盒化 | 验证成本明显上升 |
| 全托管式 | 高层业务判断 | 从需求推进到部署 | 人只保留结果责任 | 出事故时解释能力不足 |
真正的分水岭,不是有没有用模型,而是你还剩多少实现路径的解释能力。一个团队如果已经习惯让 agent 一次改十几个文件、自己跑测试、自己修错、自己决定抽象层次,而人最后只看一句“测试通过”,那它就已经不是传统意义上的辅助开发了。
它正在滑向代理式开发。
这不一定错,但你得知道自己已经站在哪儿。很多团队不是主动选择了这种模式,而是在一次次“先让 AI 改一下”的便利里慢慢滑过去的。等线上出问题,才发现真正丢掉的不是几行代码的作者身份,而是对系统如何长成这样的解释权。
它为什么突然变成主流体验?
Vibe Coding 的爆发,不是靠一句口号带起来的。它能从梗变成工作流,是因为几个条件刚好叠在了一起。
首先,模型能力跨过了开发者心里的 “可用阈值”。Stanford AI Index 2026 的 Technical Performance 提到:前沿模型在多个评测上快速逼近甚至打穿既有 benchmark;在 OSWorld 这类真实计算机任务基准上,agent 准确率从大约 12% 升到 66.3%,距离人类只剩约 6 个百分点。对开发者来说,这不是抽象的 “模型更聪明了”,而是更具体的判断:多数时候,它真的能给出一版像样的起点。
其次,工具已经不只是生成文本,而是进入了生产链路。Claude Code 官方概览把它定义为会读代码库、编辑文件、运行命令,并能与开发工具集成的 agentic coding tool。这个变化很关键:当工具从 “对话生成器” 变成 “可操作仓库的执行体”,开发者交出去的就不只是草稿,而是一整段工作单元。
最后,反馈回路太强了。一个想法几小时内变成可交互 demo,这种 “意图几乎直接转成软件” 的体验,会很快改写人的工作偏好。很多工作流不是因为边界已经想清楚才普及,而是因为体验先一步占领了习惯。
所以它的流行并不代表行业已经达成了工程共识。更准确地说,是体验优势先压过了工程谨慎。这也解释了为什么今天谈 Vibe Coding,总会同时听到兴奋、焦虑、上瘾和反思。
生成变便宜之后,验证开始变贵
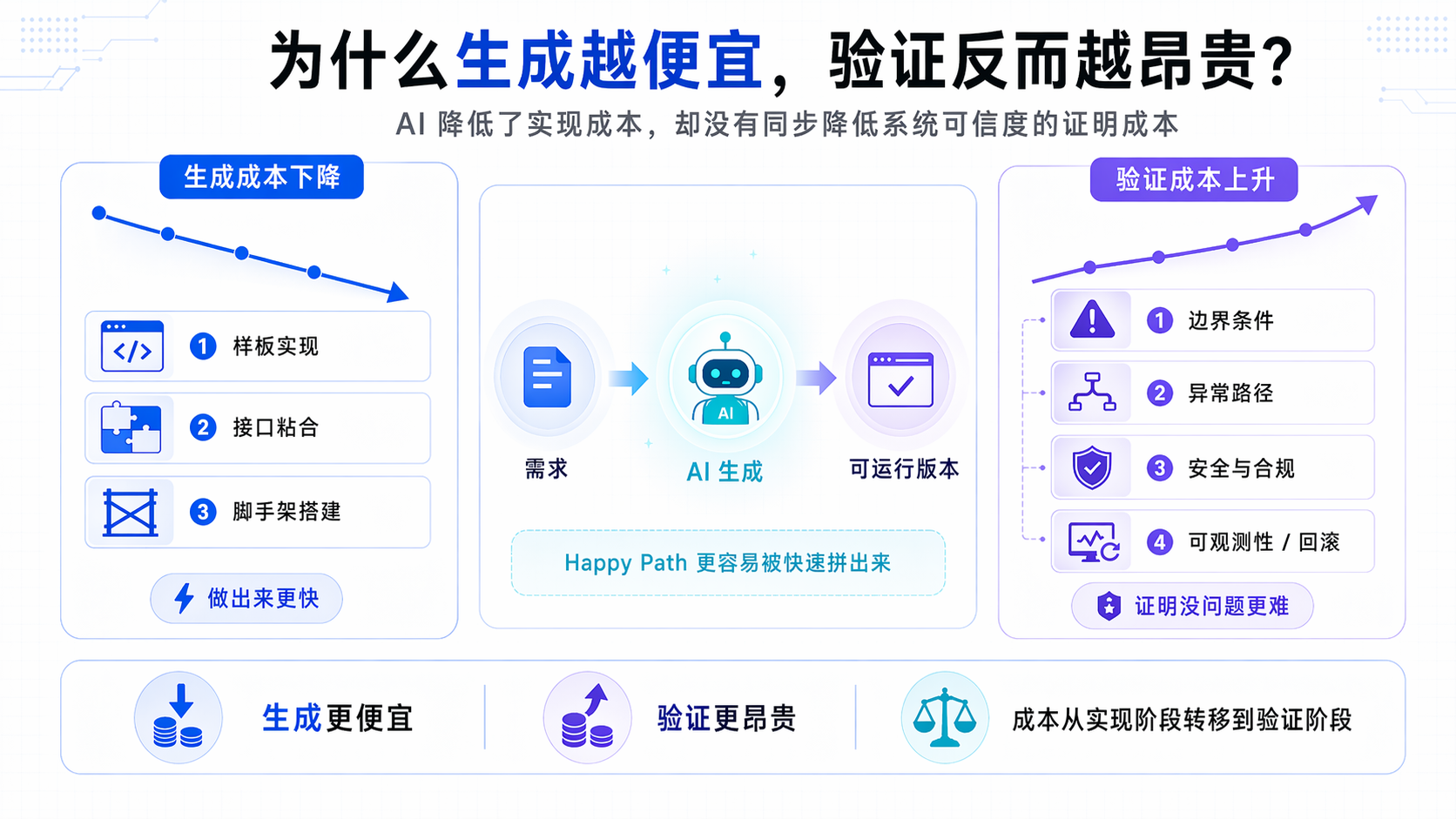
如果只把 Vibe Coding 理解成“写代码更快”,会错过这里最关键的变化。AI 确实把生成成本打下来了。过去要半天甚至一天的样板实现、接口粘合、脚手架搭建,现在常常几十分钟就能有结果。这个红利是真的,对个人开发者、小团队和原型验证尤其明显。
但工程里真正贵的,从来不是把 happy path 拼出来,而是证明它在复杂条件下不会炸。AI 改变的是生成速度,不是系统可信度的证明难度。你让模型给 SaaS 系统加 Stripe 支付,它可以很快补出前端页面、后端 webhook、数据库迁移,甚至顺手写几条测试。真正危险的问题通常在后面:
重试是否幂等,支付失败后权限回收是否一致,日志会不会泄露敏感字段,异常路径是否可观测,人工兜底流程有没有。
换句话说,AI 把 “做出来” 的成本打下来了,却没有同步降低 “证明没问题” 的成本。很多团队感受到的张力正来自这里:需求推进更快了,Review、测试、事故排查和架构解释的压力却没变小,甚至会随着 AI 输出规模一起上涨。CodeRabbit 那篇文章里有个判断很准:问题不再只是 creation problem,而是 confidence problem。
今天最累的往往不是最会写提示词的人,而是那些必须替大量 AI 输出兜底、解释和签字的高级工程师。高级工程师的工作不会因为 AI 生成更多代码而消失,反而会更多地转向判断:哪些改动能进,哪些抽象不能要,哪些测试只是摆设,哪些风险现在必须拦住。
从这个角度看,Vibe Coding 没有消灭工程成本,只是把成本从实现阶段挪到了验证阶段和责任阶段。前半段省下来的时间,如果后半段没有护栏,迟早会以返工、事故或不可维护的形式还回来。
Addy Osmani 想守住的,其实是工程判断
我认同 Addy Osmani 这一年反复强调的区分:Vibe Coding 不等于 AI-Assisted Engineering。 这不是词语洁癖,而是在区分两件事:AI 是否参与工程,以及工程判断是否仍然被人类保留。
在 Addy 对 2026 年 LLM coding workflow 的总结里,最值得看的不是工具列表,而是他把工程纪律放得很靠前:先写 spec,再写 plan,再拆小步任务;给模型足够的上下文和规则;把测试、审查、自动化检查放进闭环;坚持人类必须 review,并理解最终要 merge 的代码。这些做法看起来不炫,但守住的是一件比“写得快”更重要的事:系统判断权不能顺手一起外包。
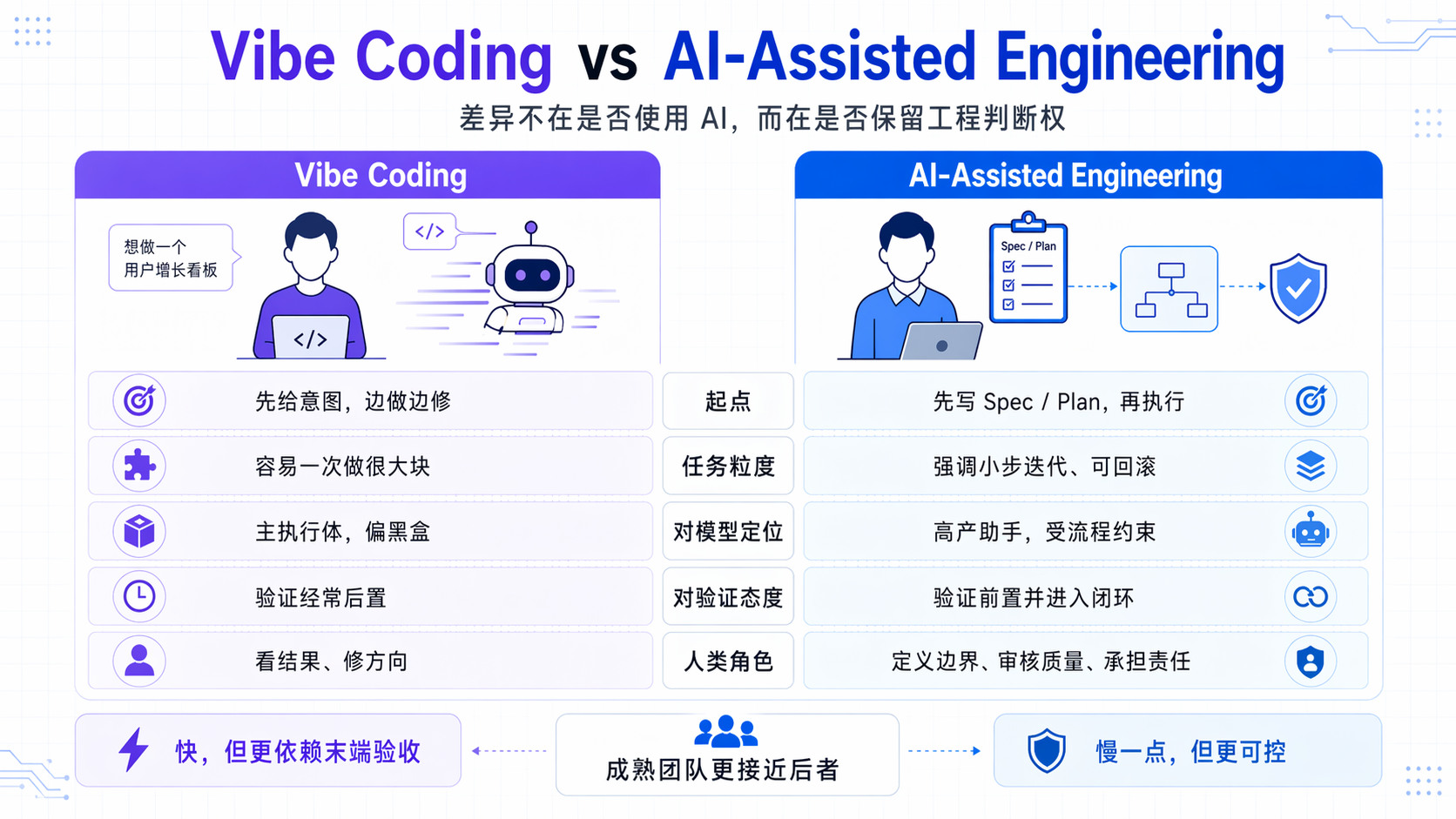
这张表可以把差异说得更直白一点:
| 维度 | Vibe Coding | AI-Assisted Engineering |
|---|---|---|
| 起点 | 先给意图,边做边修 | 先写 spec 和 plan,再执行 |
| 任务粒度 | 容易一次做很大块 | 小步迭代,方便回滚 |
| 对模型的定位 | 主执行体,偏黑盒 | 高产助手,受流程约束 |
| 验证习惯 | 经常后置 | 前置,并进入闭环 |
| 人类角色 | 看结果、修方向 | 定义边界、审核质量、承担责任 |
这背后的差别,不在某个工具,而在工作流哲学。
- 好的 AI 编程不是少思考,而是把思考前置;
- 不是少验证,而是把验证显式化;
- 不是把责任推给模型,而是把模型放进一套可审查、可回滚、可解释的流程里。
Vibe Coding 最容易制造的错觉是:“既然实现很便宜,那就先做出来再说。” 对 demo 来说,这可能正是优势。对复杂系统来说,省掉的结构化思考,通常会在调试、返工和事故复盘里补回来。
真正会被慢慢磨掉的,是解释能力

谈 Vibe Coding 的风险,很多人会先说“AI 会写错代码”。这当然是真的,但还不是最深层的问题。更麻烦的是,团队可能会慢慢失去系统解释能力。
解释能力不是读懂某个函数,而是能回答这些问题:这个模块为什么这样分层?边界为什么画在这里?一个服务失败为什么会牵动另一个服务?下个月需求变了,第一刀应该切在哪里?
这些问题靠“代码能跑”回答不了。它们靠团队对系统的持续理解来回答。
当团队习惯了“有需求就让 AI 改,改完能跑就 merge,出问题再继续问 AI”,短期看不一定会崩。AI 的确能继续修补很多局部问题。但长期看,系统增长速度会超过团队理解速度。功能还在增加,组织却越来越难解释它为什么长成现在这样。到那时,架构演进就不像设计,更像考古。
现实中的责任链也会变得很别扭:需求是你提的,架构方向是 AI 推的,代码是 AI 改的,测试是 AI 写的,问题是用户在线上报的,最后承担结果的人还是你。执行权可以外包,责任不会跟着外包。
这种“理解感下降,但责任感不下降”的错位,才是很多团队真正焦虑的地方。
哪些项目可以放开,哪些必须收紧?
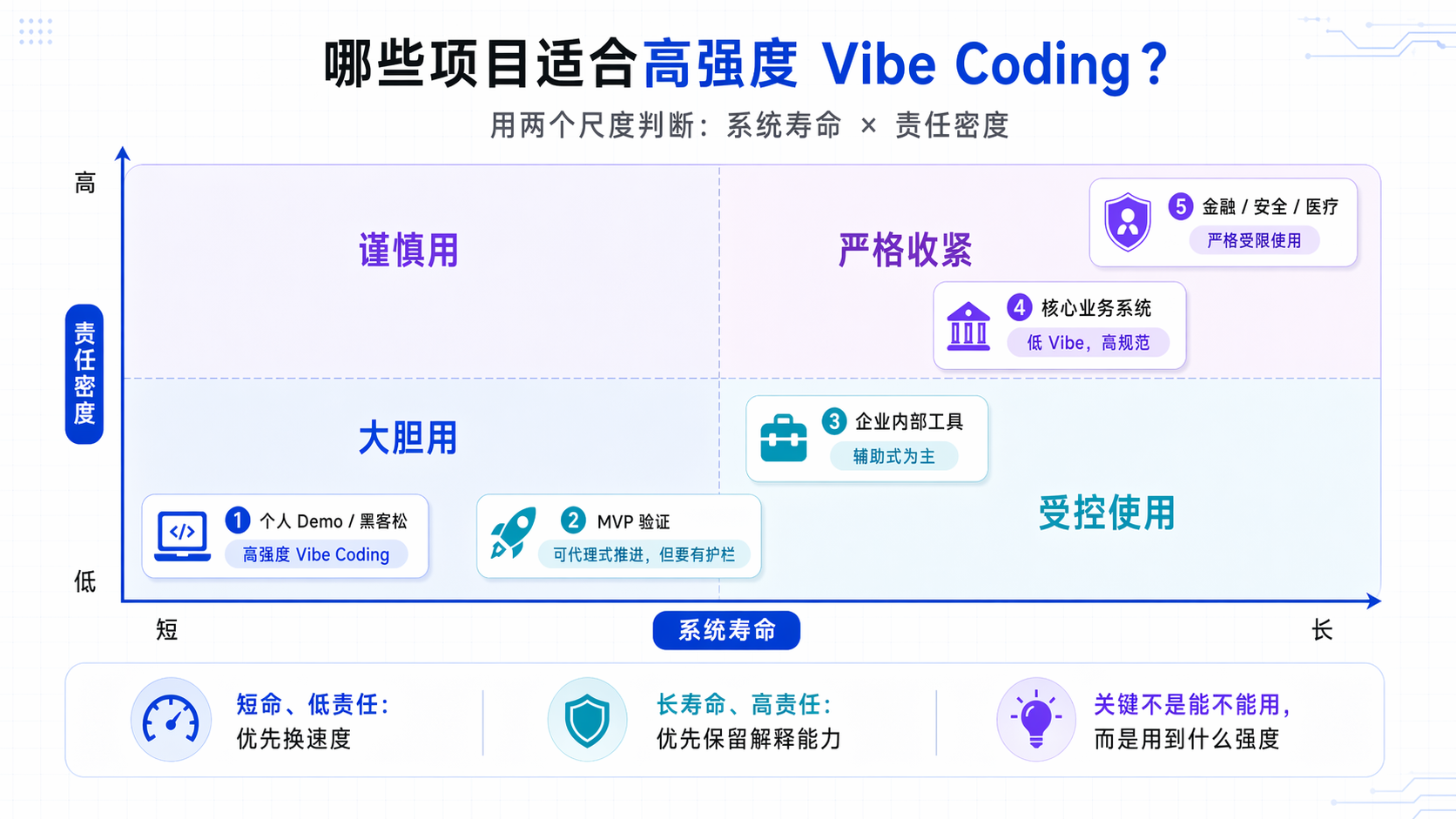
我并不认为 Vibe Coding 是原罪。相反,在很多场景里,它非常好用。问题不在于能不能用,而在于用到什么强度。
我习惯用两个尺度判断:系统寿命和责任密度。系统寿命看这个东西是活三天还是活三年;责任密度看它出错以后会不会伤到钱、客户、数据、合规或品牌。寿命越长、责任越重,越不能把结构理解和验证责任交给即兴生成。
| 项目类型 | 更合适的用法 | 原因 |
|---|---|---|
| 个人 demo / 黑客松 | 高强度 Vibe Coding | 目标是验证想法,不是长期维护 |
| MVP 验证 | 代理式,但要有护栏 | 可以用速度换反馈,但要保留回滚 |
| 企业内部工具 | 辅助式为主 | 后续维护真实存在,别把坑留给未来 |
| 核心业务系统 | 低 Vibe,高规范 | 事故代价高,解释能力必须保留 |
| 金融 / 安全 / 医疗相关 | 严格受限使用 | 合规和验证成本通常高于生成收益 |
这个框架的意义,是把争论从“支持不支持 AI 编程”拉回工程决策。短命、低责任项目可以激进一点;长寿命、高责任系统就应该更像受控的 agentic engineering,而不是彻底交给 vibes。
别把 AI 当隐形 CTO
如果一定要给今天的 coding agent 找一个组织角色,我更愿意把它看作一个极其高产、知识面很广、不会累,但经常自信犯错的执行体。它不是隐形 CTO,也不该拥有最终判断权。
这个定位会自然导出分工。
低责任、高重复、容易验证的工作,很适合交给它:脚手架、重复性重构、文档草稿、测试样板、规则清晰的机械改造。这些任务最适合用 AI 换吞吐,因为错了也容易看出来,改回去的成本也低。
高责任、难验证、影响长期结构的问题,则必须由人类团队握住所有权:架构边界、安全约束、数据模型演化、事故根因判断、关键链路抽象设计。难点不在于“有没有一个答案”,而在于“这个答案是否值得承担长期后果”。AI 很擅长给出一个像答案的东西,但它不会替你承担后果。
我会怎样给团队定规矩
如果把上面的判断落到团队实践里,我会从这六条开始。它们都不新鲜,但在 AI 输出变多以后,会变得更重要。
1. 先写 spec,再让 AI 动手
不要从“帮我把这个做了”开始。至少写清目标、约束、不能破坏的边界和验收标准。spec 不必长,但要能让人和模型处理同一个问题。
2. 任务切小,改动可回滚
别让 AI 一次改几十个文件再统一 review。小步生成、小步验证、小步提交,本质上是在给验证成本设置上限。
3. AI 交付必须绑定测试和运行反馈
没有测试、没有最小运行验证的 AI 改动,不应算完成。AI 在护栏内迭代很强,没有护栏时也很擅长自信地说“已经完成”。
4. 高责任系统先补 observability
日志、metrics、trace、feature flag、回滚机制,在 AI 时代会比“代码是不是优雅”更救命。你面对的是更高频率的变更,不是更少的变更。
5. 架构所有权必须归人
模块怎么拆,边界怎么定,哪些抽象需要长期稳定,这些不能完全交给模型即兴发挥。架构不是一次输出,而是一套持续演进的约束。
6. Review 要看能不能解释
Review 不能只问“能不能跑”。还要问:为什么这层放在这里?下个月要改,第一刀切哪里?当前最脆弱的点是什么?如果负责人答不上来,说明系统理解已经落后于系统增长了。
这些规则看起来保守,其实是在给更高强度的 AI 协作创造条件。没有它们,团队得到的往往不是更快的工程,而是更快地产生未来要还的债。
结论
Vibe Coding 最吸引人的地方,是它让软件第一次如此接近“用自然语言直接制造”。但软件工程那些老问题没有消失:能跑不等于可靠,生成不等于理解,上线不等于可维护,快也不等于对。
所以我对它的判断并不悲观,也不狂热。它不是 “AI 取代程序员” 的简单故事,而是一场工程分工的重排:控制面上移,验证压力上升,责任重新集中到人类身上。
成熟团队不会拒绝它,也不会神化它。该快的地方尽量快,该慢的地方必须慢;适合外包给 AI 的执行工作大胆外包,必须由人类承担后果的判断权牢牢握住。
过去写代码的门槛是“会不会实现”。接下来,更高的门槛会变成:当 AI 已经能大量生成实现时,你是否仍然比它更懂系统、边界、验证和后果。未来最稀缺的工程师,不只是写得快的人,而是能在生成越来越便宜的时代,仍然说清楚 why、where 和 what breaks 的人。
参考资料
- CodeRabbit: A semantic history: How the term 'vibe coding' went from a tweet to prod
- Andrej Karpathy on X: "There's a new kind of coding I call 'vibe coding'..."
- My LLM coding workflow going into 2026
- Vibe coding is not the same as AI-Assisted engineering.
- Claude Code overview
- The 2026 AI Index Report
- Technical Performance | 2026 AI Index
Continue your reading
When you finish this article, use these paths to continue the thread.
// tags
Explore adjacent topics and move sideways through the knowledge graph.